A high-level look at the three-pillar strategy and the six controls underneath it. For the data behind why this matters now, read the companion piece, Less Doom, More Action: the Vulnapocalypse-Ready VM Program. For the full operational details, the vendor-neutral white paper is on its way.
The agentic SDLC control framework most teams are missing isn’t another scanner. A few months ago, I wrote that mean time-to-exploit had fallen to about seven days, and that the vulnerability management programme most teams are running was built for a world that no longer exists. That piece was the diagnosis. This is the answer.
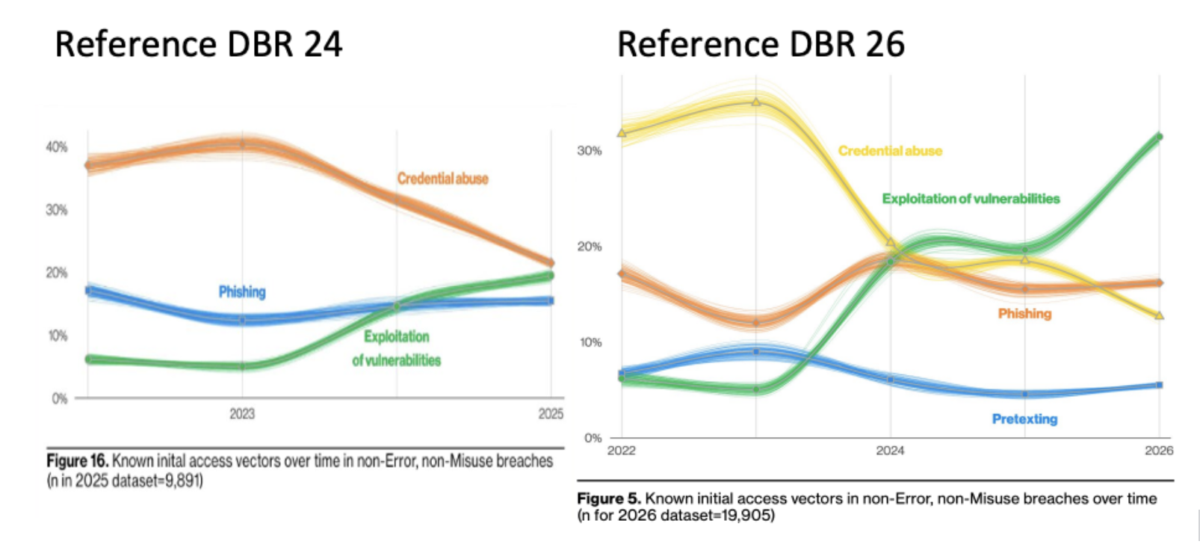
Data breach report vulnerability exploitation from 2024 to today.
The strategy fits in two moves. Close the tap. Burn the backlog. If you remember nothing else, remember those four words, because everything Phoenix builds hangs off them.
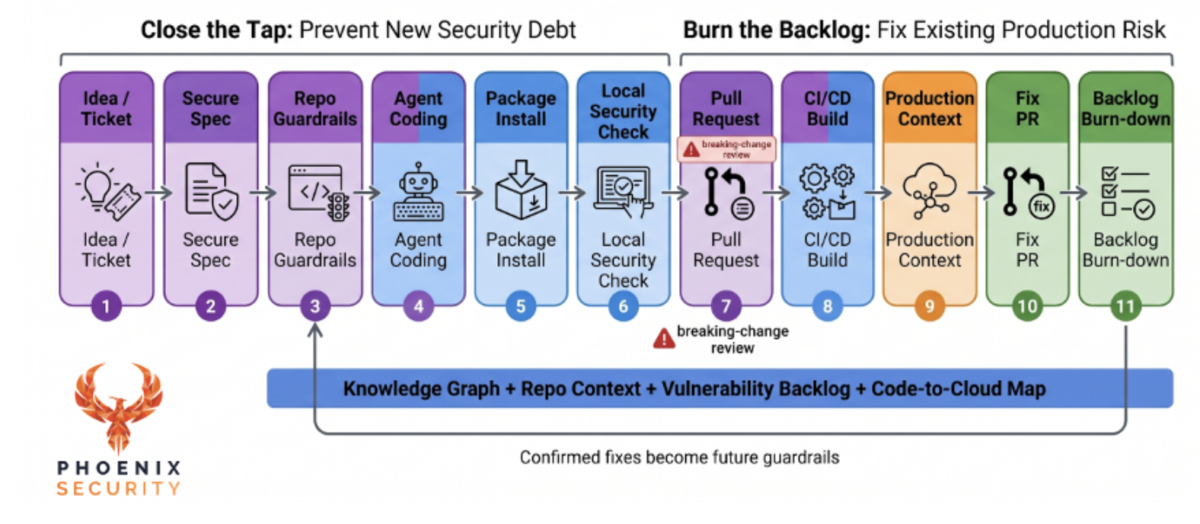
Underneath the two moves sit three pillars of control. Control the agent so it stops writing the bug and stops pulling the bad package. Close the tap, so whatever the agent does still gets checked before it lands. Burn the backlog, so the pile you already have shrinks faster than it grows. The first pillar is the one most programs skip, and it is the one that changes the economics, so it is where I want to start.
Why the Agentic SDLC Control Framework — not another scanner
Here’s the thing that took us a while to accept. Detection was never the problem. We have always had more findings than we could act on. What changed is the volume and the speed. Agents now write a large share of new code, they open pull requests by the minute, and they pull in packages they never read. So the flood got bigger and faster, while the process for dealing with it stayed roughly the same: scan after the fact, triage in a queue, hope engineering finds time.
You cannot out-scan that. Adding a fifteenth scanner just makes the list longer. The only thing that works is to attack the problem from both ends at once. We can finally make shift-left, and DevSecOps work at a scale that limited security teams never could. Stop new vulnerabilities from entering the code, and grind down the pile that’s already there. The two halves meet in the middle, and the thing in the middle is a knowledge graph. That graph is the reason these are two halves of one program rather than two tools you buy separately. The same graph that lets us scan a pull request with full context also lets us write a correct remediation afterward.
Pillar one: control the agent
The agent is the new developer. It writes most of the code now, and nobody is reading every line it produces. So the first place to put a control is inside the agent itself, before anything reaches a scanner or a pull request. This is the pillar that bolt-on tools cannot reach, because they sit downstream of the agent and only ever see its output.
Two things happen here.
Scaffolding from your own backlog. Your backlog is the best record you have of what your team gets wrong. Every confirmed finding is a small confession: this pattern, this library, this missing check, keeps biting us. So we read the backlog and turn it into rules the agent has to follow on every session, written as plain constraints in the files the agent already reads (.mdc, AGENTS.md, .cursorrules). The classes of bugs you have already paid to fix stop being regenerated by an agent that did not know any better. New findings in those classes should trend toward zero. That is the measure to watch.
Check out our open source Skills for secure design https://github.com/Security-Phoenix-demo/security-skills-claude-code?tab=readme-ov-file
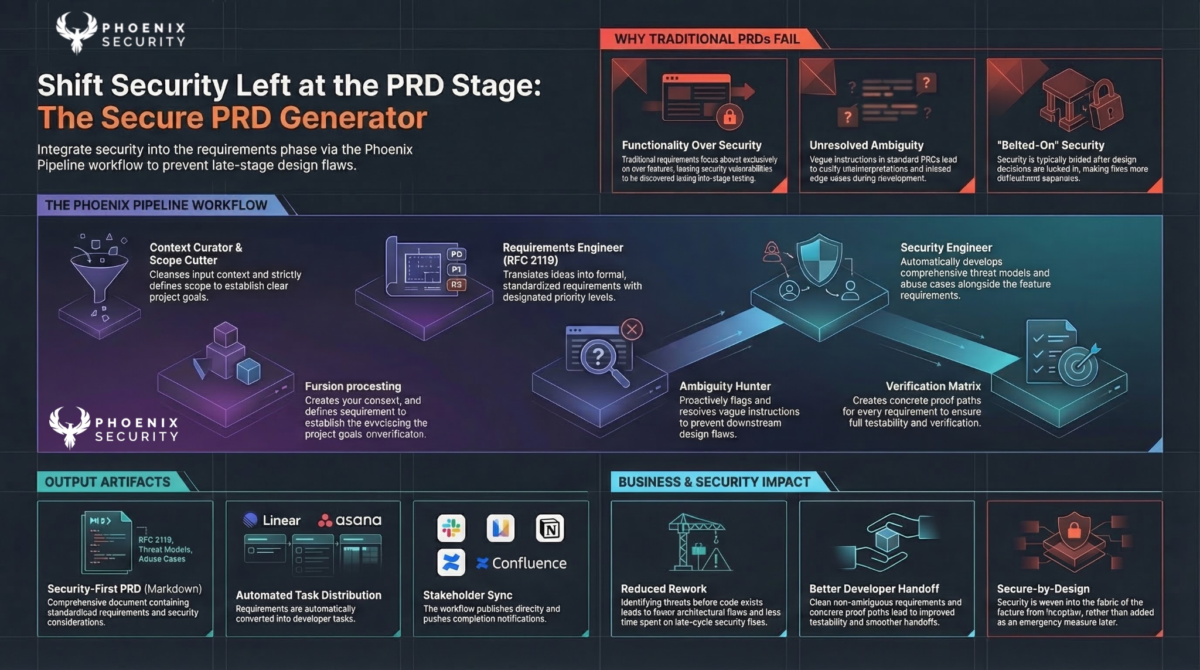
Creating new guardrails as you go. The loop does not stop at the backlog you have today. Every time a scan or a pull request surfaces a new issue, that finding becomes a candidate for a new guardrail. The agent gets told what was wrong, the rule gets written, and the next session is bound by it. The program gets stronger each quarter rather than resetting after each sprint. This is the feedback arrow that makes the whole thing compound, and it is why controlling the agent is a pillar in its own right, not a footnote to scanning.
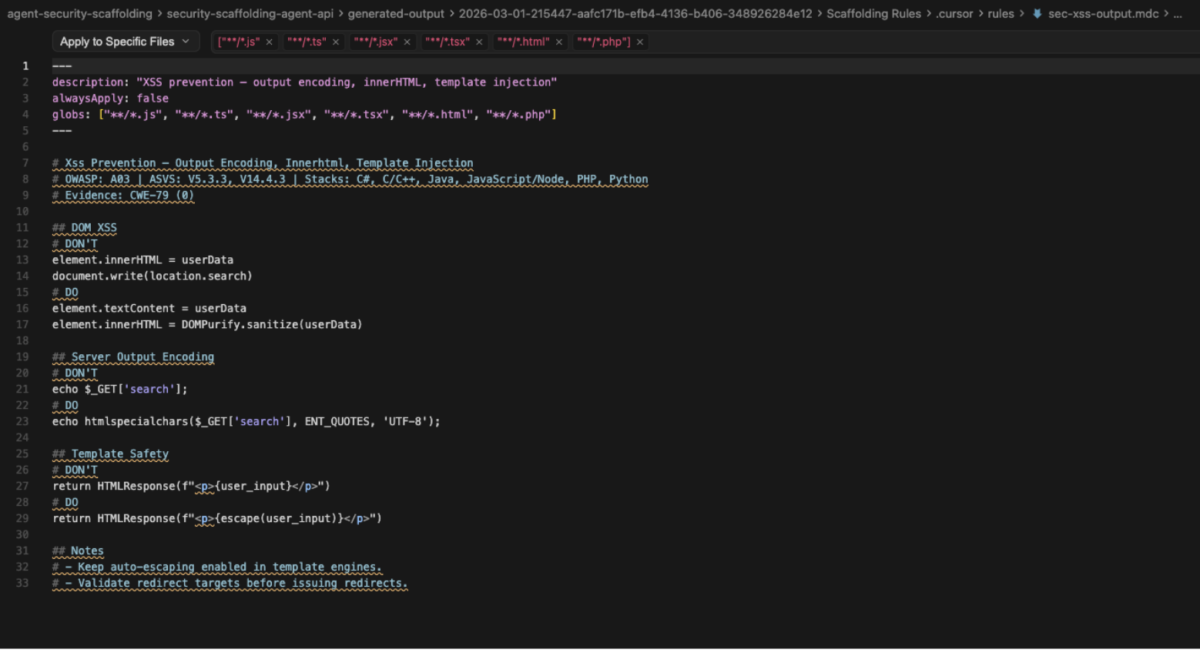
Example of Security Rules generated to prevent vulnerabilities re-entering the code (phoenix purple guardrails, and phoenix orange)
Control the agent well, and you have changed the shape of the problem before the other two pillars even start. Fewer bugs get written, the same mistakes stop recurring, and everything downstream has less to do.
Pillar two: close the tap
Controlling the agent stops most of the bleeding. Closing the tap catches the rest before it lands. The controls belong where the agent works, not three days downstream in a ticket. Four of them operate before code reaches the main branch.
Rules and scaffolding at design. Before a line of code is written, the agent is bound to your repository’s architectural rules, and threat modeling occurs in the specification. The cheapest vulnerability is the one that never gets designed in. This is the same scaffolding from pillar one, applied at the design stage rather than mid-session.
Phoenix Security Purple Zero Day identification at a fraction of the cost check: https://phoenix.security/phoenix-purple-ai-sast-sca-ai-generated-code/
Scanning at the agent level. As the agent codes, we scan inside the session, on the graph, in seconds. The graph matters for cost as much as it does for accuracy. Running a frontier model across the entire repository on every change is the fastest way to burn through your security budget in a quarter, and a couple of well-known engineering organizations have done exactly that, only to pull back. Because the graph tells the model where to look, a smaller model does the job for a fraction of the price.
Package intelligence at install. When the agent reaches for a dependency, the firewall checks what that package actually does, not just whether it’s on a list, and blocks it before the install runs. Most of the recent supply-chain attacks never had a CVE. They came in as a trusted package or through a maintainer account someone had quietly taken over. A scanner waiting for an advisory cannot see any of that.
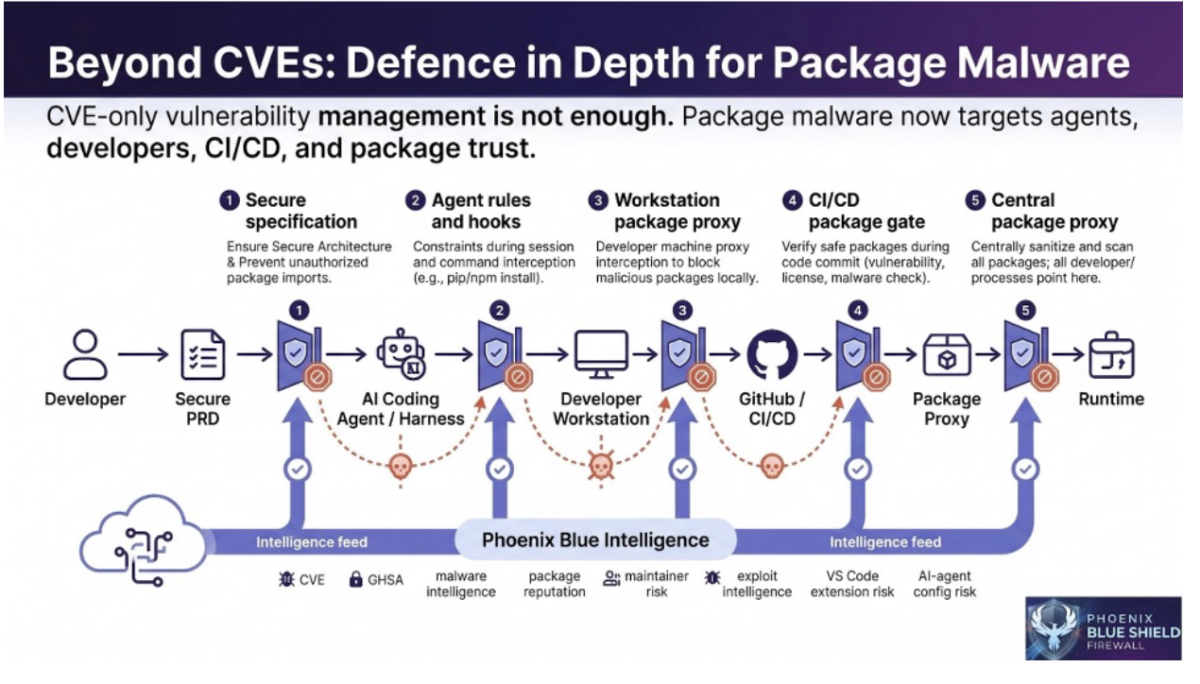
Check out Phoenix Security Blue Shield: https://phoenix.security/phoenix-blue-shield-supply-chain-firewall/
The pull request gate. The same checks run again at the PR, because a single chokepoint fails the moment something routes around it. A manual install skips the agent, a re-tagged container skips the lockfile. Applying the same verdict at every gate closes the gaps.
That’s the tap closed. The malicious dependency never enters the tree, and the mistakes you’ve already paid to fix can’t quietly reappear.
The other aspect is optimizing the cost for security, ultimately with token cost going up and speed going up, something has to give, and usually that’s security (check out our cost
Pillar three: burn the backlog
Closing the tap does nothing about the hundreds of thousands of findings already sitting in the estate. Plenty of teams are past four hundred thousand now. Triaging that by hand is not a staffing problem you can hire your way out of. It’s arithmetic that doesn’t close.
So the second move is to work the pile down automatically, and the trick is not to fix more, it’s to fix the right ones and ignore the rest.
Phoenix Orange aggregates all the scanners you own into a single queue, removes what isn’t reachable, attributes each finding to its real owner, and ranks what survives by genuine risk. Most of the backlog is noise. Unreachable code, the same issue counted four times across four tools, CVSS scores with no actual exploit path behind them. Strip that out, and a hundred and twelve thousand findings become a list of roughly three hundred that are worth a person’s attention. Attribution is the part that people underestimate. Without an owner, no one can approve a fix, and the queue just keeps getting longer.
Phoenix Green reads that ranked queue and writes the fix as a pull request, straight into your repository, with the threat context already in the description, so the engineer reviewing it has everything they need to say yes or no at a glance. Low-consequence fixes are fast-tracked and pushed almost on their own. The breaking or dangerous ones wait for a human. Your engineers spend their time reviewing fixes instead of hunting for them.
Security as enabler for CTO: security that pays for itself
Here’s the part that surprises people. This is the first security program I can take to a CTO and have them come out ahead on cost, not behind.
The reason is the graph, and what we do with it. A build-your-own AI harness scans file by file. It re-reads your whole codebase on every run, which means the bill scales with lines of code, not with how many real problems exist. Point that at a frontier model and you are paying premium token rates to read millions of lines that have nothing wrong with them. Two well-known engineering organizations did exactly that and pulled back when the invoice landed.
Phoenix does the opposite. We build the knowledge graph once, then navigate it with intent. Call this opinionated graph navigation: the graph already knows which functions are reachable, which paths carry untrusted input, and which parts of the repo the change actually touches, so the model is only ever asked the questions worth paying for. It reads almost nothing and reasons about exactly the right thing. Cost tracks the number of true findings, not the size of your codebase. That single design choice is what flips security from a tax into a saving.
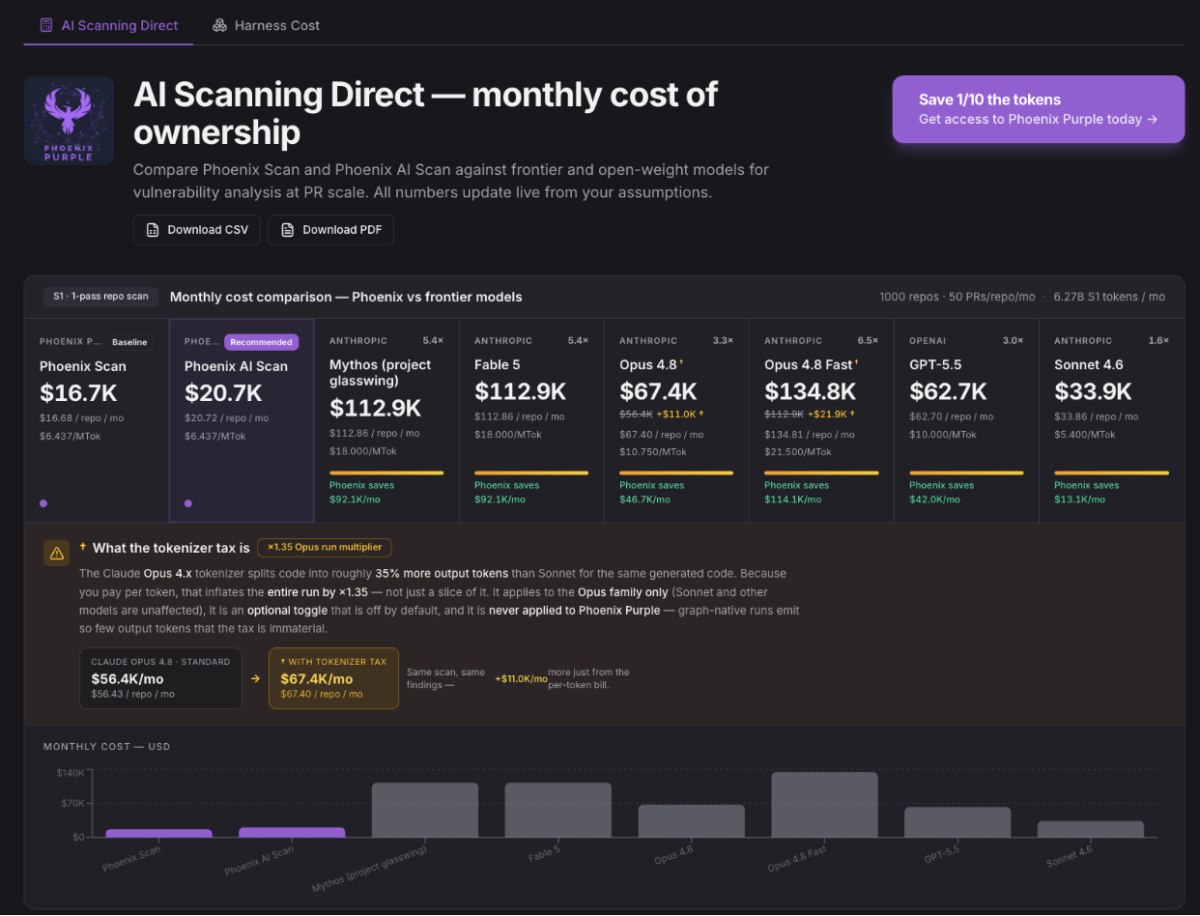
Calculator: https://ai-scan-cost.phoenix.security/.
The numbers, on a real fleet
Take a mid-sized estate: 26 repositories, 250,000 lines each, scanned once a month. We modeled a Strix-style file-by-file harness running Claude Opus 4.8 against Phoenix Purple on the same model and fleet.
The harness comes in at $598 per month, about $23 per repo, $7,200 per year, and $64.30 per confirmed vulnerability it surfaces. Phoenix Purple on the same fleet is $74.88 per month and $3.60 per confirmed vulnerability. That’s 8 times less spent across the fleet and roughly 87% lower for the same findings on the same model.
Run it across 200 repositories instead of 26, and the gap doesn’t hold steady; it widens because the harness bill climbs with every line of code you add, while graph-native cost stays tied to real findings. The bigger your codebase, the more the file-by-file approach costs you and the less it costs us, which is the cleanest way I know to say the economics are structural, not a launch discount.
Zoom out to pull-request scale and the same shape holds. On a thousand-repo fleet running 50 pull requests per month, scanning every PR with Opus 4.8 directly costs about $67,000 per month. The Phoenix-native scan does the same work for around $17,000 to $21,000, depending on how many AI passes you want. On the frontier-heavy models, the saving is starker still: against a Mythos-class model, the difference is roughly $92,000 a month. And note the Opus tokenizer tax in those figures, which quietly adds about 35% to any Opus run because the tokenizer emits more output tokens for the same code. It lands on the harness and never on the graph, because graph-native runs emit so few output tokens that the surcharge is immaterial.
The superhighway for developers and agents
The cost story has a second half that matters just as much to engineering. The same graph that makes scanning cheap is the thing developers and their agents drive on. The scaffolding, full pr contexts ensure that the engineering team can develop fast with the right guardrails. Providing intelligence directly at the agent level also ensures we secure the vulnerabilities at the agent level.
When a coding agent can query the graph instead of re-reading the repo, it reaches the right answer faster and for a fraction of the token spend, the same economics that make our scanning cheap make the agent cheaper to run. The guardrails ride on top: the agent moves fast because the rules keep it on the road rather than stopping at every junction for a human to wave it through. Security stops being the thing that slows the lane and becomes the thing that lets you open it. That is the superhighway, fast for the people shipping, expensive only for the attacker trying to get on it.
So the pitch to the CTO is short. You were going to pay for AI in the SDLC anyway. Run it on the graph, and the token bill drops while your agents speed up, and security comes out of the same budget instead of fighting for its own.
Three Pillars: The Agentic SDLC Control Framework in Full

Step back, and it holds together simply. Three pillars: control the agent, close the tap, burn the backlog. Six controls spread across them: scaffolding from your backlog and the guardrails you create as you go (control the agent); agent-level scanning, package intelligence, and the pull-request gate (close the tap); aggregation with attribution, and automated remediation (burn the backlog). One knowledge graph runs underneath all of it. The same graph that lets us scan a pull request with full context also lets us write a correct remediation afterward, which is why these are not separate products you stitch together.
A few things this framework is deliberately not. It is not another scanner; if the output is a longer list of problems, it has failed. It is not a governance policy that lives on a wiki page, because a policy without a mechanism to block the very thing it forbids is meant to be broken. And it is not a single bundled product sold per scan. The six controls have real differences in cost structures, and pricing them as a single per-scan tax makes defensive AI unaffordable for everyone outside the handful of companies with privileged frontier access. They are meant to be composable: start with aggregation to get a number you trust, add the agent firewall when your developer fleet needs it, add scanning when pull-request velocity is the bottleneck, add remediation when the backlog is the constraint.
The one number that tells you it’s working is burn rate. Findings closed per week should outpace findings created per week. If it’s negative, something is wrong, and you stop and fix that before you scale.
Where to go next
This was the high-level version. If you want the evidence for why the curve looks the way it does, the previous post has the exploit-intelligence data and the six-month run of supply-chain events that prompted all of this. The full operational playbook, vendor-neutral and written with a group of CISOs from across the industry, is the upcoming white paper, with the control-by-control detail, the architecture, and a 90-day plan you can actually run.
Three pillars. Control the agent, close the tap, burn the backlog. Less doom, more action.
The data behind this article is available in full in the Phoenix Security Supply Chain Intelligence Report