Key Takeaways
- Mythos is here, but other models are capable at compromising
- Mean time-to-exploit sits at 7 days. Down 81% versus 2025. Zero-day rate at 58.4%, up 29%. The fitted curve projects 1 day by 2028, 1 hour by 2032, 1 minute by 2037. Source.
- The last six months produced a Mythos-class supply chain event roughly every three weeks: TeamPCP, Axios, Sandworm npm worm, React Server Components CVE-2025-55182, Shai Hulud Second Wave 2.0, and three Claude Code CWE-78 CVEs.
- 41% of new code is AI-generated. More code at higher velocity equals more entry points. Scanning a flood of generated code downstream is a losing strategy.
- Sophistication is climbing, not falling. Anthropic’s Mythos model autonomously produced working exploits against 72.4% of the vulnerabilities it discovered on the Firefox JS shell. Project Glasswing handed that capability to twelve companies. Commodity models are catching up fast.
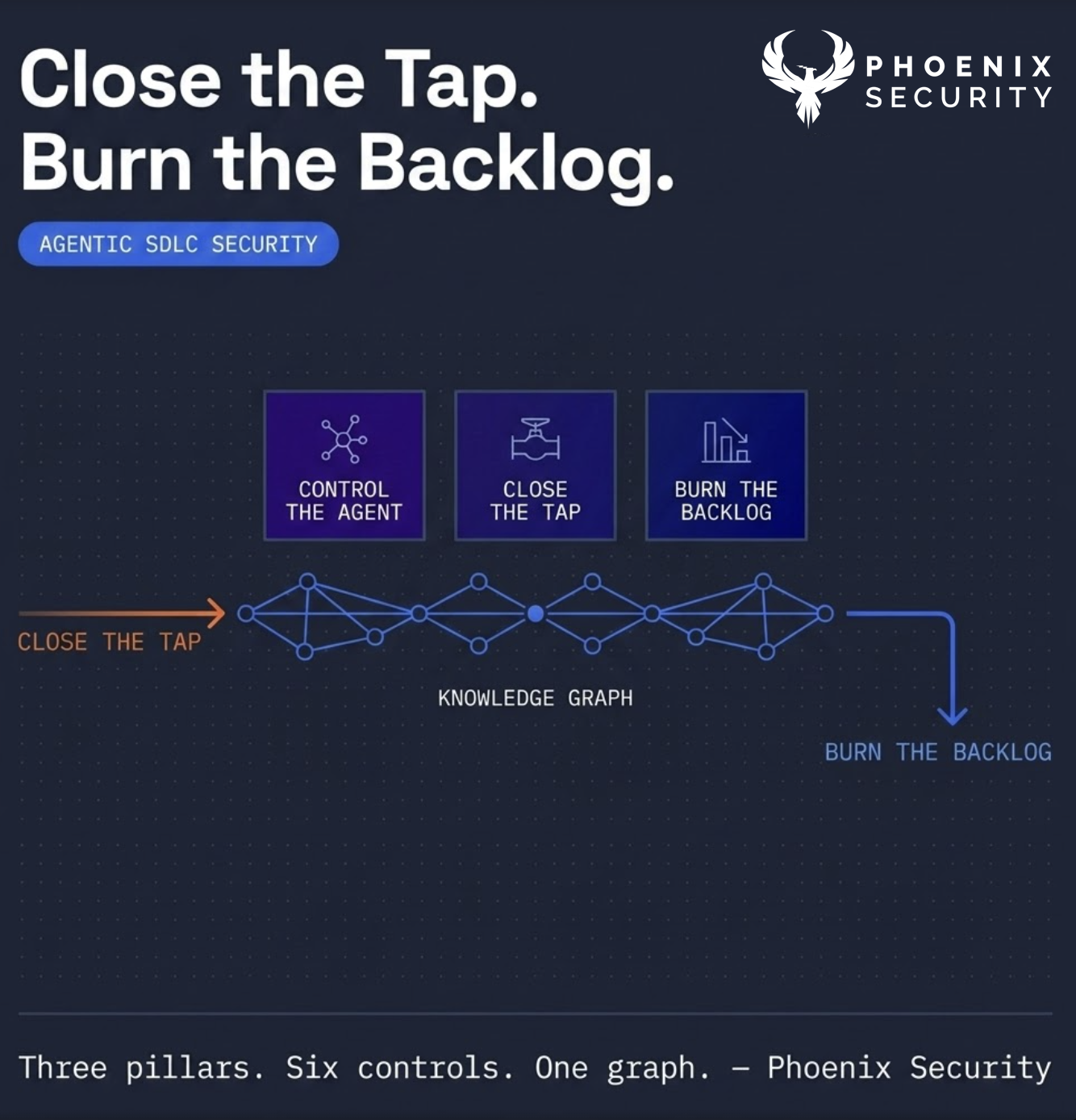
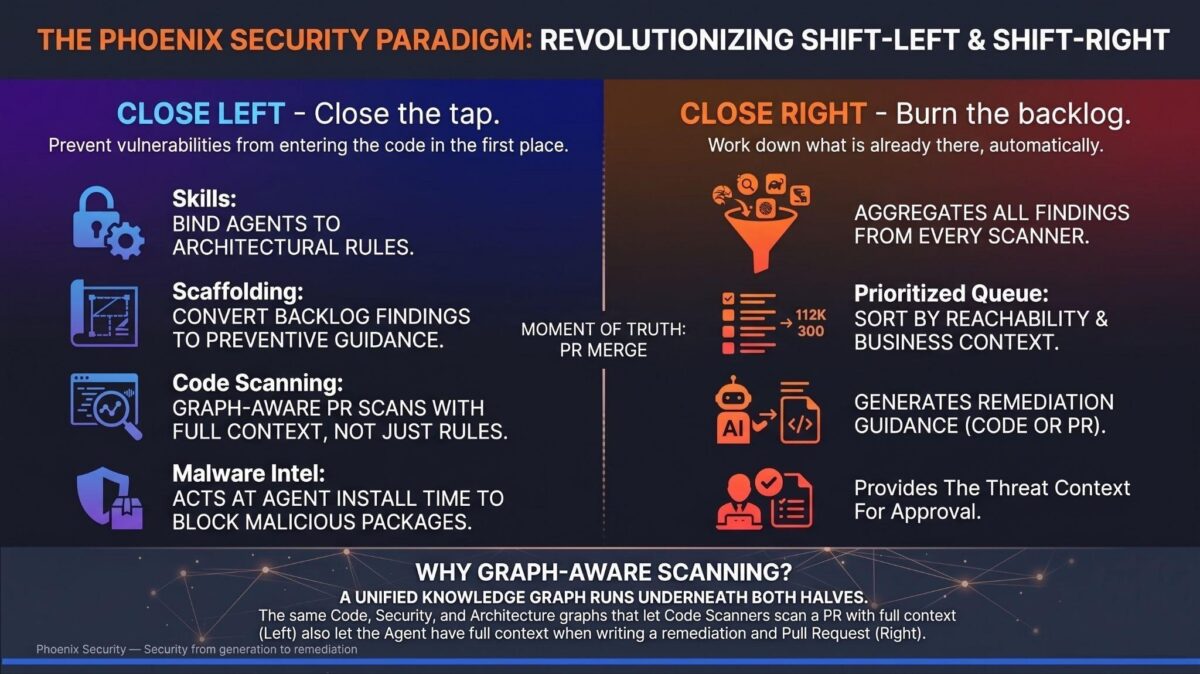
- The defensive answer has two halves that meet in the middle: Close the tap (prevent vulnerabilities at generation) and Burn the backlog (auto-remediate what is already there). Six controls. One knowledge graph underneath. One badge to wear: Vulnapocalypse-Ready.
1. The Numbers Are Not Drifting. They Are Falling Off a Cliff
The Phoenix Exploit Intelligence dashboard reads like a stress test of every assumption baked into modern vulnerability management.
Mean time-to-exploit: 7 days. Down 81% versus 2025. Zero-day rate at 58.4%, up 29% in twelve months. 4,433 CVE-exploit pairs in the active corpus. The exponential decay model fits at R-squared close to 1.0 across the full sample. Linear assumptions are dead. The curve is steep, and it is accelerating.
Walk it forward. 1 year was reached around 2020. 1 month around 2023. 1 week has passed this year. 1-day projects to 2028. 1 hour to 2032. 1 minute to 2037. That projection is not science fiction. It is a fitted curve on real CVE-exploit pairs from zerodayclock.com cross-referenced with phxintel. security.
I am not arguing that 2037 will arrive on schedule. I am arguing that the program your team is running today was designed for the 2018 curve. Patch SLAs are measured in 30/60/90 days. Scanner reports are reviewed weekly. Manual triage on a quarterly cadence. That program is already three orders of magnitude behind the speed of exploitation, and the gap widens every quarter.
2. The Last Six Months Were the Preview, Not the Climax
Look at what has landed since November 2025. I am not cherry-picking; this is the ecosystem-on-fire reality:
- Mini Shai Hulud with simplicity and compromise of official packages and leveraging ai injections. The campaign is technically distinct from the previous Shai-Hulud waves (September 2025, November 2025) in three ways. It uses Bun-as-runtime to bypass Node.js execution monitoring. It injects persistence into AI coding agent configuration files, including .claude/settings.json SessionStart hooks and .vscode/tasks.json folderOpen triggers.
- Claude Code CVE-2026-35020 / CVE-2026-35021 / CVE-2026-35022. Three CWE-78 command injection flaws in the CLI itself, credential exfiltration confirmed, shell injection in the CLI, editor, and auth helpers. The coding agent is now part of your attack surface.
- TeamPCP / Telnyx (March 2026, Day 7 of campaign). WAV steganography over the PyPI supply chain, Windows persistence via msbuild.exe, and audiomon. service for K8S lateral movement, credential cascade through a YOU API gateway vector. C2 at 83.142.209.203. Patch immediately, rotate all credentials, and block the C2.
- Axios compromise. Plain crypto-js v4.2.1 hidden RAT dependency, propagated through the standard npm install path, hit CI/CD and production servers via clean-dep-A and clean-dep-B chains.
- Sandworm_Mode npm worm. 19 malicious packages weaponizing CI pipelines, stealing credentials, and injecting into AI assistant tooling.
- React Server Components CVE-2025-55182. CVSS 10.0. Affected versions 19.0, 19.1.0, 19.1.1, 19.2.0. High exploitation activity from Chinese threat actors observed within hours of disclosure.
- Shai Hulud Second Wave 2.0. 25,000 npm repos affected, 425 libraries compromised, self-replicating worm behavior. The original Shai Hulud was a warning. Wave 2.0 is the curve doing what curves do.
Every one of those events sits on the same exponential curve. The aggregate behavior is the story, not any single CVE.
3. Why This Cycle Is Different. Sophistication Is Climbing, Not Falling
The reflex argument is that “the low-hanging fruit gets picked first, then the curve flattens.” That argument is wrong on this curve. Three reasons.
Reasoning models commoditize exploit development. Anthropic’s Mythos run on Firefox’s JavaScript shell autonomously discovered vulnerabilities and produced working exploits against 72.4% of them. Over 99% of what it surfaced remains unpatched at time of writing. Mythos was a frontier capability six months ago. The replication papers are already public. Local-model approximations are within reach for anyone with two H100s and a weekend.
Malicious LLMs are now a SaaS market. WormGPT at 109 EUR per month. FraudGPT at 90 EUR per month. WolfGPT at $150. Evil-GPT at $10. DarkBERT, BLACKHATGPT, EscapeGPT. A reproducible academic survey (arxiv.org/abs/2401.03315) catalogued the pricing tiers more than a year ago, and the catalogue has only grown.
The exploit window keeps shrinking against named clocks. Cloudflare observed exploitation of CVE-2024-27198 (JetBrains TeamCity auth bypass) 22 minutes after the public PoC. The headline image from the Phoenix research deck shows the actual UTC timestamps: JetBrains release at 14:00, public CVE disclosure at 14:59, Rapid7 PoC at 19:23, Cloudflare attempted exploitation at 19:45. From PoC to attempted exploitation: 22 minutes. The internal Phoenix research clock now shows three-minute attempts on certain classes of post-disclosure exploits.
The volume side is just as hostile. GitHub data referenced by Mostaque puts AI-generated code at 41% of all code committed right now. The curl project lead has gone on record that AI-generated bug reports are wasting developer time at industrial scale. Bigger codebases, generated faster, with patterns the model learned from training data that is two to three years old. The math is brutal: more code, more entry points, less human review, faster attackers.
The low-hanging fruit is not “picked.” It is growing faster than it can be picked. And the attackers writing the picking machines now have reasoning.
4. Defending 2018 Volume With 2018 Process Is Madness
A decent VM team in 2018 ran 8 to 14 scanners, ingested around 40,000 findings annually, triaged in weeks, and routed work through Jira. That program does not survive the current numbers. 400,000 open findings are realistic now, because agents generate more code and scanners catch more problems. Backlogs of 4M findings exist; I have seen them.
If a single engineer triages one finding per minute for an 8-hour shift, that is 480 findings per day. A 4M-finding pipeline needs 8,333 engineer-days a year just to triage before anyone fixes anything. Nobody has that headcount. Nobody is getting it.
So the position is simple. Vulnerability management without AI-grade automation is, at this point in the curve, madness. Not hyperbole. Arithmetic.
You either fight AI with AI, there is not another thesis. This blog is not doom and gloom but more a sober response focused on what’s next instead of just the world is on fire.
As industry, we have been advocating for Devsecops, Shift Left, with AI, we can truly do this, but not by throwing a frontier model and eating the security budget in months
The answer is not the model, it is the process, controls throughout the AISDLC (ai software development lifecycle) from generation to pull request block to remediation
Is not just about this or that model as the picture below shows:
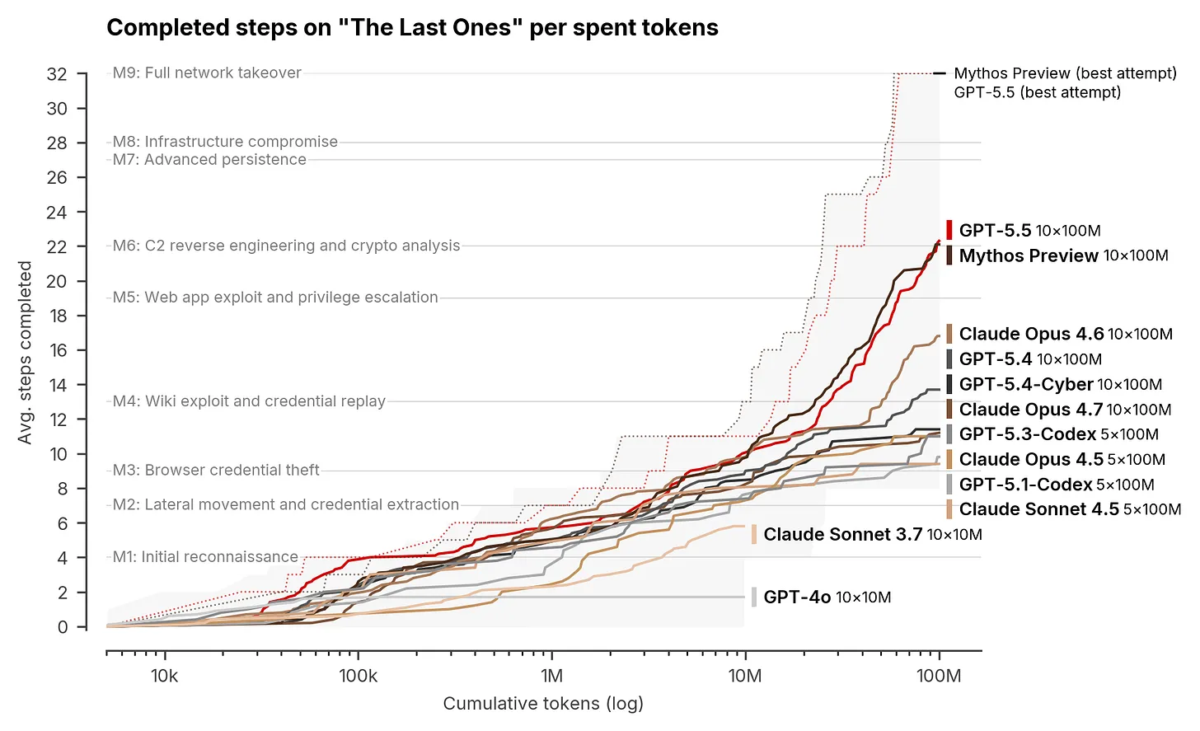
The UK AI Security Institute (AISI) utilizes a comprehensive evaluation suite, featuring 95 narrow cyber tasks across four difficulty levels in a capture-the-flag format, designed to assess offensive security skills, including vulnerability research and exploitation.
The core of this evaluation is “The Last Ones” (TLO), a 32-step corporate network attack simulation. Modeled on a real enterprise kill chain, TLO spans four subnets and approximately twenty hosts, covering the entire process from initial reconnaissance to full network takeover via privilege escalation and lateral movement. The AISI estimates a human expert would typically need about 20 hours to complete this full chain.
Claude Mythos Preview became the first model to successfully solve TLO end-to-end, a feat detailed in the AISI’s (evaluation of the model’s cyber capabilities). The model completed the full 32-step chain in 3 out of 10 attempts, averaging 22 steps across all trials. In comparison, the next-best model at the time, Claude Opus 4.6, only averaged 16 steps and never achieved full completion.
Mythos Preview also demonstrated significant performance on expert-level narrow cyber tasks—which no previous model could complete before April 2025—succeeding 73% of the time. Each attempt was allocated a 100-million-token compute budget. The AISI noted that the model’s performance continued to improve up to this limit, suggesting that, like other aspects of AI, cyber capabilities may adhere to scaling laws. Ironically, this reliance on scaling and additional compute represents a supply chain constraint, even for a company like Anthropic.
Protect yourself with the latest threat intelligence, get access to PHOENIX BLUE Today
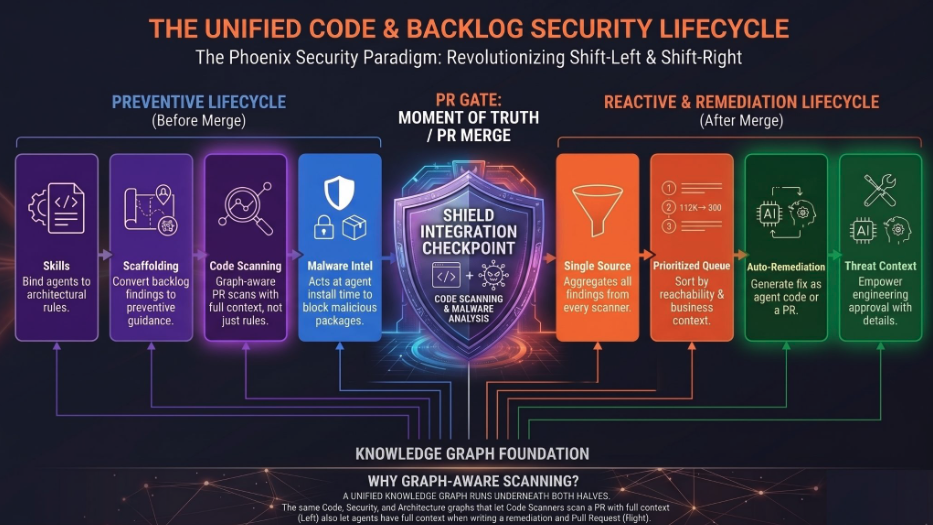
5. Close the Tap. Stop Filling the Bathtub While You Bail
The Mythos-Ready program is the response, and the thesis is uncomfortable but simple: if attackers have reasoning, defenders need reasoning. And reasoning at scale is only economical against curated context, not against the open web.
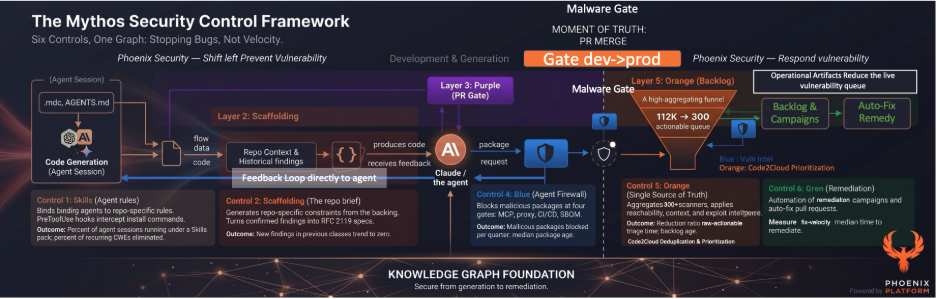
Operationally, the program splits into two halves that meet in the middle. Close the tap. Burn the backlog. Both run on the same knowledge graph, which is the union of three layers: the code graph (function calls, library lineage, container chains), the security graph (taint paths, source-to-sink mapping, command execution), and the architecture graph (service topology, API boundaries, deployment context). The graph is the reason the two halves are the same program, not two different products.
Close the tap is four controls operating before code lands.
Skills. Phoenix Purple Skills sit inside the agent session at the design level. They bind Claude, Cursor, Codex, Windsurf, or Cline to repo-specific architectural rules as the agent writes the PRD. The agent cannot specify an authentication pattern that violates the rule pack without being intercepted and corrected. The open repository ships specification skills that hook into Claude Code, Cursor, and Codex. Authentication patterns embedded in the spec. Authorization bounds are defined upfront. Threat modeling delivered as a skill, not a meeting.
Scaffolding. Secure defaults written as .mdc, AGENTS.md, GEMINI.md, .cursorrules. The agent reads them on every session. The input is your existing backlog. Every confirmed finding becomes a permanent constraint, expressed as an RFC 2119 requirement that the agent is bound by. Your backlog is the best ground truth for what your team gets wrong, and the rules can prevent existing vulnerabilities from being re-generated.
Code scanning at the agent level. Graph-aware SAST, SCA, IaC, secrets, container scans run inside the agent session in under 15 seconds. Triple-pass adversarial validation keeps false positives under 10%. The agent scans, the agent reviews, the agent calls a human only when an architectural or critical decision is needed. The Phoenix Purple Hunt mode goes further and searches for exploitable, chainable vulnerabilities beyond a single scan.
Malware and CVE intel as an MCP plugin. Phoenix Blue acts at the agent at install time. The MCP tool inside the agent session blocks malicious packages before npm install fires. The local install proxy is the next gate. CI/CD lockfile scanning is the safety net. Dual-LLM adversarial intelligence with 77 signals mapped to MITRE ATT&CK v16. Median age of package at install drops below 2 hours when the firewall is enforced on the developer fleet.
The four controls compound. Skills stop the agent from designing the bug. Scaffolding stops it from reintroducing one you have already seen. Code scanning at the agent catches the rest before the PR is opened. The MCP malware prevents a poisoned dependency from ever entering the tree.
Stages of a program to be mythos-ready
The key to the program is having a maturity evolution and evolving the controls gradually or rapidly, pushing towards the left and closing the tap
The Multi-Stage control aligns with the modern AI SDLC multi-stage security pipeline, enabling proactive management and remediation of vulnerabilities throughout the Software Development Lifecycle (SDLC). This methodology aims to “shift left” security to the earliest stages and efficiently “squash right” to address the existing backlog.
The security pipeline is segmented into three primary stages:
Part 1 – Design and Generation
Part 2 – Pull request Gate – this is the border of commit
Part 3 – Followed by a comprehensive Squash Right phase. Each phase leverages specific agents and intelligence to maximize security impact
Part 1 – The design and pre-commit stage
1. The Design Phase (Purple: Scaffolding)
This is the ultimate “Shift Left” stage, focusing on preventing vulnerabilities before any code is written. The core principle is to “close the tap before the vulnerabilities get generated.”
- Objective: Embed security requirements directly into the Product Requirements Document (PRD) and design specifications.
- Key Tooling/Skills: The Scaffolding Agent (Purple), as demonstrated in the security-skills-claude-code repository. This includes the Secure PRD Generator skill, which pushes security into the requirements stage.
- Outcome: A rigorous, security-aware product design that minimizes the attack surface from the outset.
The agent enables secure design whilst the rules anad constraint (scaffolding) constrain the agents from generating (or in this case re-generating) malicious code.
2. The Generation Stage (Blue and Purple: Fast Feedback)
This phase occurs while the code is actively being generated, emphasizing speed and full context to provide immediate feedback to the development agents.
- Objective: Catch and correct vulnerable code as it is being written.
- Key Tooling/Skills:
- Blue Malware Agent: Focuses on vulnerability intelligence with full feedback loops, allowing the agent to make real-time security decisions.
- Purple Agent: Provides full context with optimized analysis and token usage, or uses skills with good but potentially sub-optimal feedback (e.g., vulnerability scanning).
- Principle: Have the intelligence and vulnerability analysis as close to the agent as possible to ensure maximum effectiveness.
- Relevant Skill Suite: The Security Assessment Suite, which includes four AppSec skills and active hooks for integration into the agent environment.
Part 2 – the Gate stage
3. The Gate Stage (Contextual Blocking)
This is the traditional “blocker” stage, activated when code is committed and aggregated as a Pull Request (PR).
- Objective: Perform a final, contextualized security check before merging code into the main branch.
- Key Action: Scanning and blocking with context to prevent vulnerable code from entering the repository.
Part 3. The “Squash Right” Strategy (Backlog Management)
The “Squash Right” phase addresses existing debt by prioritizing and remediating the backlog of historical vulnerabilities.
4. The Attribution Stage (Orange)
Before remediation can begin, it is critical to know who owns the vulnerability.
- Objective: Accurately map vulnerabilities to the correct assets and responsible teams.
- Key Action: Attributing the right assets to the right team.
5. Prioritization and Risk Assessment (Orange and Blue/Threat Intel)
The focus shifts to efficiently tackling the most critical risks in the existing backlog.
- Objective: Define the most impactful remediation work.
- Key Actions:
- Prioritization (Orange): Basic sorting and ranking of vulnerabilities.
- Risk-Based Prioritization (Blue and Threat Intel): Leveraging real-world threat intelligence and context to determine actual exploitability and business risk.
6. Remediation and Threat Hunting (Green and Purple)
The final step is the execution of fixes to maximize the return on effort.
- Objective: Achieve the biggest win through targeted remediation.
- Key Actions:
- Remediation (Green): Providing detailed, effective fixes, which can be asset-specific or cross-asset.
- Zero-Day Hunting (Purple): Inserting the Purple agent at this stage to actively hunt for 0-days and perform large-scale triage, detecting if multiple low/medium vulnerabilities can be chained into a major attack, or assessing if a vulnerability is genuinely exploitable in its current context.
6. The Phoenix Security Vision – Burn the Backlog. Make the Heap Smaller While You Stop Adding to It

Burn the backlog is the right side of the program. Two controls.
Phoenix Orange. Aggregation, attribution, deduplication, reachability, and prioritization across every existing scanner, plus pentest, risk-accepted, and runtime sources. 112,000 raw findings collapse into a 300-item actionable queue. Attribution is what makes this work. Without ownership nobody can approve a fix, and without dedup the queue is just a longer list. Phoenix Orange routes findings to the right team via PYRUS YAML, code-to-cloud lineage, and CMDB sync. The 467,000 to 8,000 reduction we measured on container vulnerabilities at one customer is the quantified version of what aggregation plus reachability does to noise.
Phoenix Green. Reads from Orange’s queue. Generates remediation pull requests automatically with full threat context: CWE → CAPEC → MITRE → threat actor, baked into the PR description. The engineer reviewing the fix has everything needed to approve or reject in a single glance. SCA on Gradle and Java is live today. Maven, npm, and pip land across 2026. SAST autofix in H2 2026.
The link between the two halves is the graph. The same code graph that lets Phoenix Purple scan a PR with full context also lets Phoenix Green write a correct remediation PR. Same graph. Same reasoning. Different output.
7. The Vulnapocalypse-Ready Badge (Yes, Wear It)
Heads of vulnerability management deserve a name for what they are running. Mythos-Ready is the technical descriptor. Vulnapocalypse-Ready is the badge.
The joke is in the name. The audit underneath is serious. If your program has Skills bound to your agent, Scaffolding generated from your backlog, agent-side code scanning on every session, a malware firewall on your install proxy, an aggregated single source of truth on your backlog, and auto-remediation PRs flowing into your repos, you wear the badge. Print it on a sticker. Stick it on your monitor. Give one to every engineer who deployed it.
8. Going Even Further Left. PRD-Stage Specification Skills
The fastest fix is the one that never has to be written.
Phoenix Purple Skills now operate at the PRD design level, not just the code level. The open repository at github.com/Security-Phoenix-demo/security-skills-claude-code ships specification skills that bind the coding agent before a single line of code is generated. The agent generates the spec under the constraint set, scaffolds the implementation under the secure defaults, scans on session close, and calls Phoenix Blue at install. By the time a PR lands on the right side of the merge gate, four prevention controls have already filtered it.
This is what shift-left was supposed to mean. Not “buy a SAST scanner and put it in the IDE.” Not “block the build at the last minute.” Bind the agent at design. Constrain the generation. Scan inside the session. Block bad packages before they enter the dependency tree. Then, on the right side of the merge gate, aggregate, attribute, deduplicate, prioritize, and auto-remediate whatever made it through.
That is the program. Six controls. One knowledge graph. One platform. Composable by design, with different unit economics for different controls so the total cost of running the program reflects the actual work being done, not a bundled-scan-per-finding tax.
9. The Window Is Closing
The 7-day mean time-to-exploit is not a stable number. It is a snapshot on a curve that fits exponential decay almost perfectly. Every quarter the window narrows by a measurable amount. Teams that get vulnapocalypse-ready in the next two quarters compound their advantage. Teams that treat this as next year’s problem will discover the curve does not wait for budget cycles.
The economics work against the laggards, too. Mythos-class capability cost north of 50M USD when it was incorporated into Project Glasswing. Six months later, commodity models reach a meaningful fraction of that capability for one percent of the cost. By the time it reaches the lower tiers of the threat actor market, the gap between what attackers can run and what your scanner can detect will not be measurable in days. It will be measurable in CVEs they exploited while your team was scoping the procurement of the SAST tool you should have replaced two years ago.
The good news is the defensive playbook is shippable today. Skills, scaffolding, agent-side scanners, malware MCP, aggregation, and auto-PR remediation: all six controls exist and run on a single platform with a single asset-credit model. The 90-day plan is concrete enough that a 500- to 5,000-engineer organization can have all six running by the end of Q3. Not theoretical. Not roadmap. Shippable.
Teams who move now wear the Vulnapocalypse-Ready badge. Teams who wait get to explain to the board why the breach in Q4 was not preventable. Both outcomes are available. Pick.
Next Steps
- Run the backlog audit. How many findings sit in unreachable code? How many are in agent-written PRs from the last quarter? How many duplicate across scanners? What is the ratio of raw findings to actionable queue? You cannot fix what you have not measured. Phoenix Orange does this in 30 days.
- Pick the top ten repositories with the most AI-generated PRs in the last quarter. Generate Skills and Scaffolding from their existing backlogs. Deploy the agent-side scanner and the Phoenix Blue malware MCP across every developer machine running Claude Code or Cursor. Day 30 to Day 60.
- Turn on auto-remediation. Phoenix Green generates remediation PRs at a rate faster than new findings arrive, or the program is miswired. The Day 90 gate is non-negotiable: every AI-generated PR runs through all four prevention controls before merge, and the burn rate must be positive.
References
- Phoenix Exploit Intelligence dashboard: phxintel.security/exploit-intelligence.html
- Zero Day Clock: zerodayclock.com
- Phoenix Mythos-Ready Program v3 (April 2026)
- CSA “The AI Vulnerability Storm” v0.8
- Cloudflare Application Security Report 2024 Update: blog.cloudflare.com/application-security-report-2024-update
- Malicious LLM market survey: arxiv.org/abs/2401.03315
- Phoenix open security skills repository: github.com/Security-Phoenix-demo/security-skills-claude-code
Phoenix Security Claude Code CVE disclosure: phoenix.security CVE disclosure.
The results are clear:
- Bazaarvoice saved $6.3M in developer time and for teams removed critical in the first weeks of adoption
- ClearBank cut critical container vulnerabilities by 96–99% and reclaimed 4 hours per engineer per week.
- A global AdTech company saved an equivalent of 1.5M in development hours and reduced SCA-to-container noise by 82.4%
- Optimizely has been able to act on vulnerabilities sitting on the backlog.
Or learn how Phoenix Security slashed millions in wasted dev time for fintech, retail, and adtech leaders.