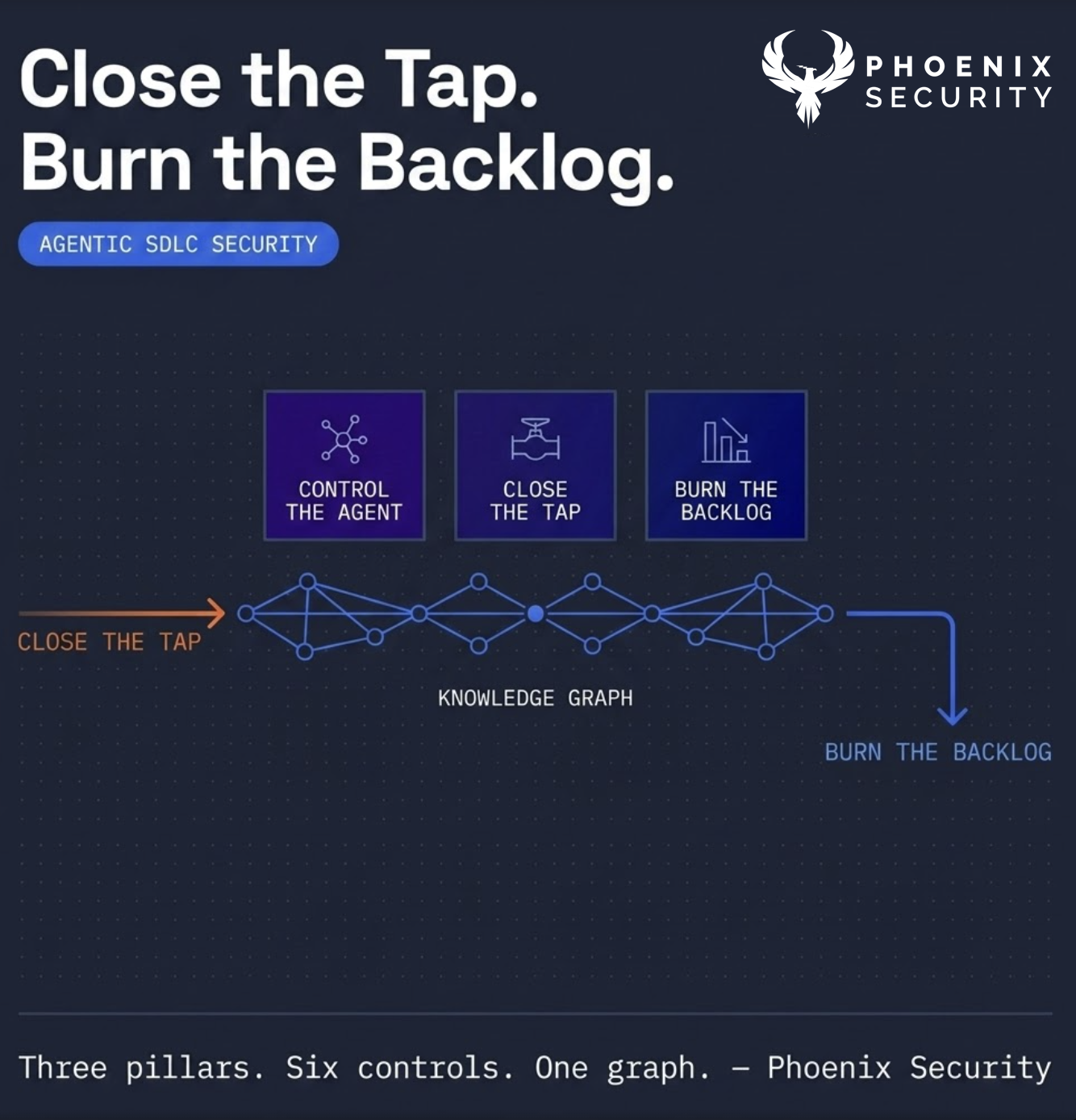
Francesco Cipollone was a guest on the Applicaiton Security weekly podcast ASW #239
Contents
ToggleTimes:
3:22 – Intro
4:10 – Shift left, shift everywhere shift smart
6:10 – regulation and accountability
8:12 – asset management, sbom, pbom
10:00 – developer view, fixing things
12:00 – Vulnerability and context
14:00 – importance of vulnerability management with context and business context – SLA
14:23 – Risk
16:00 – risk-based vulnerability management – what to prioritize
17:30 – SLA
19:21 – Maturity Framework
21:00 – Risk strategy and pushback – Maturity
24:00 – Vulnerability software engineer and risk to business
27:00 – Application security the business view
29:00 – Security and development, KPI and the importance in stress time
33:00 – Innovation / Chat GPT / And focusing on the basics
34:00 – Akiran – Innovation from appsec team
37:00 – Business case for application security
39:00 – Threat model, risk model how they fit together
40:00 – Telling the story for vulnerability
43:00 – Evolution of vulnerability management and the sea of salt
45:00 – Definition of maturity and how far they want to be
47:00 – SLA, Complexity in measurements
48:00 – NIS2 and cybersecurity act for SBOM
49:00 – Appsec in 3 words
50:00 – Links, Vulnerability management framework
51:26 – conclusions
Key Segments/Summary
Resources:
Framework: https://phoenix.security/vulnerability-management-framework/
Books on metrics: https://phoenix.security/whitepapers-resources/data-driven-application-security-vulnerability-management-are-sla-slo-dead/
Vulnerability aggregation and prioritization https://phoenix.security/whitepapers-resources/whitepaper-vulnerability-management-in-application-cloud-security/
Shift left: https://phoenix.security/shift-everywhere/
Vulnerability management talk: https://phoenix.security/web-vuln-management/
Vulnerability management framework playlist (explained) https://www.youtube.com/playlist?list=PLVlvQpDxsvqHWQfqej5Gs7bOd-cq8JO24
How to act on risk: https://phoenix.security/phoenix-security-act-on-risk-calculation/
Segments Summary
TRAFFIC REPORT
This week we chat with Francesco Chipalone about modern phone management frameworks. Also share two interviews from last week’s RSA conference. It’s time for Application Security Weekly for security professionals. Drive safely and stay tuned for application security weekly.
SHIFTING LEFT
Francesco: We have to do more than just shift left and deal with volumes. Mike: I’ve seen a move towards reclamping back all the security tool. Is everybody’s responsibility, but security accountability. Francesca: Getting back in control is getting the buy-in from the business.
VULNERABILITY THREAT MANAGEMENT: ASSET MANAGEMENT
Start with an asset inventory. No one has a really good asset inventory, do they? No, I think it’s incremental approach. It’s the incremental approach that you can do but without. Let’s not forget what’s important like asset management around maturity.
SHIFT SMART, SHIFT LEFT, SHIFT RIGHT: SECURITY AND DEVOPS
A lot of it sounds like security is expanding. But there’s got to be a communication as well. We need to communicate more into risk. So you’ve described shift left, shift right. I like the idea of shifting up and we’ll get to maybe whatever it looks like for shift down.
SECURITY RISK AND THE BUSINESS
The Vulnerability Management Maturity Framework aims to reduce risk at the highest level. Not every business wants to operate at the same level. There is a fear factor of automatic calculation of risk versus human actually judging what is the risk. A change in culture and a transformation needs to happen.
VULNERABILITIES IN THE CLOUD: VALIDATION AND MANAGEMENT
Vulnerability management framework divided in different area from discovery to prioritization to aggregation to resolution process procedures and action and measurement. Any security company needs to find fight against a spreadsheet or a tableau. It could make for much more fruitful and interesting conversations along the developer team.
ON THE SECURITY OF THE DEVELOPMENT TEAM
A developer will never have a glorified conversation with a product owner. The vast majority of developers just want to know what they need to fix. Security is a major aspect of software quality resilience. If you don’t have KPI that says x amount of story points or being at a specific risk level for an organization, you lose the ability to have a conversation.
VALIDATION MANAGEMENT: THE APPSEC TEAM’S RESPONSIBILITY
As we’re leaning on then the risk level, does that shift more of the responsibility onto the AppSec team? Are there tooling or spreadsheets that can help with this approach? By looking at insights and having the data centralized, it really can bring the value of an AbSec team.
WHAT’S THE NEXT STEP TOWARD INNOVATION IN APPSEC?
The next logical step is creating an asset register. And you can do that by reverse engineering the vulnerability information that you have. The problem is it’s all disjunct. It’s complicated to connect to all the service. Even as fresh we should be.
SECURE VS. DEVELOPMENT: THE NEED FOR A SECURITY DEFAULT
How do you make the case to actually spend time on developing a library? How do you measure that? Make the case for security with ROI like everybody else does. Fixing vulnerability and patching is super important but fixing the vulnerability that matters most is even more important.
THE NEXT STEP IN CYBERSECURITY MATURITY
The thing that I’m still wondering about is how, you know you’re ready to move from one segment of maturity to the next one. Each set of maturity levels have steps and have actions. It’s up to you to define how far you want to be to a maturity level.
A LESSON ON SECURITY RISK MANAGEMENT
Francesco: When we say SLA, that’s a very sort of big broad paintbrush which we’re stroking with. He says SLA is a data point that you can use to create a story. Using risk and intimate better way to control, he says.
FLOODING WITH VULNERABILITY MANAGEMENT
We ask all of our guests to describe AppSec in three words. For the vulnerability management framework, we have a Slack channel. In place of the new segment, we’ll be running two interviews from last week’s RSA conference. Stick around for the RSA interview segment coming up.
Transcription
You’re listening to Radio KASW. That was overdrive by Laser Hawk. Time for the morning traffic report, and phones are backed up on the CVE Expressway as it just passed 200,000 records last week.
Major delays at the intersection of CI and CD to an overturned truck carrying a bunch of CVSS scores. They’re all under 3.9. However, traffic is still blocked by an AbSec team checking out the scene.
There’s major construction down at the infrastructure as code, but once you’re past the on ramp, traffic is moving quickly. It’s stop and go along C Street due to memory safety activity, but they’re opening up new lanes. It’ll be rust and go pretty soon.
No delays on I 239, so shift gears and hit that pedal on the right. Which means this week we chat with Francesco Chipalone about modern phone management frameworks and how to focus on fixing what’s important. No new segment this week.
Instead, we’ll share two interviews from last week’s RSA conference. Drive safely and stay tuned for application security weekly. This is security weekly for security professionals.
By security professionals. It’s the show to learn the latest tools, techniques and processes necessary to understand DevOps application security and cloud security. Your trusted source for the latest application security news, it’s time for Application Security Weekly.
Struggling to secure all your applications? With modern identity services, you’re not alone, but with Identity Orchestration, you can say goodbye to refactoring and complexity. Strata Identity helps you modernize app identity at scale while mitigating security risks and simplifying policy management. Maintain a consistent security posture and simplify policy management with Identity Orchestration.
If you’re ready to simplify your identity environment and improve your app security, share your IAM challenge with the Strata team to get a brand new set of earbuds, just visit Securityweekly.com Strata to learn more. That’s securityweekly.com
strata. Imperva is the comprehensive digital security leader on a mission to help organizations protect their data and all paths to it. Only Imperva protects all digital experiences from business logic to APIs, microservices the data layer and from vulnerable legacy environments to CloudFirst organizations with an integrated approach combining network, application and data.
Security, imperva protects companies ranging from cloud native startups to global multinationals with hybrid infrastructure. Start a free trial today and quickly protect your web applications@securityweekly.com. Imperva this is episode 239, recorded May 1, 2023.
I’m your host, Mike Shima. I’m here with John Kinsella. Hello, John.
Mike, I appreciate the trust you put in me and what’s clearly an important time for you and the show. I hope you understand that I strive to provide highest level of service and I take your hello very seriously. Wait.
I think this is AI. John, bring back the humans. We also have Akira.
Is this human Akira? We haven’t seen you in a while. Oh, yeah. It’s human.
Akira. Alive and in the flesh. Well, at least you’re back.
We’ll work on John over the break. If you weren’t able to attend chat GPT or RSA conference this year Security Weekly and Cyber Risk Alliance. Have you covered? Our hosts sat down with over 30 executives at this year’s event to bring you the latest and greatest announcements from the show.
To find all of our coverage, please visit securityweekly.com RSAC. Francesco Ship alone is a multistart upper and a cybersecurity professional.
Francesco was the AppSec and cloud security lead for HSBC. He led cloud security for AWS Professional Services and previously consulted with the United Nations. He is also Chair of the Cloud Security Alliance, a published author, podcaster and public speaker.
Hello, Frank. Thank you for joining us. Hello, Mike.
Hello, John. Hello, Kira. It’s great to be here.
Back here, ranting about applications, in fact, back here, indeed. We had you last on in episode 177, so we’ve had a couple of numbers in between then, but this time you want to talk about volumes again, especially shifting. And I thought that I had a cheat code for shifting left.
I thought we could go up, up, down, down, left, right, left, right, BA. And that solves all of our security problems, but apparently not. So, Francesca, we have to do more than just shift left and deal with volumes.
Tell us about this. Yeah, I think somebody else made exactly that joke when I say shift left and up, up, down, left, left, right, communicate. Up, push down.
I think we started talking about shift left back in the days and I published a couple of articles around the shift left history and what we wanted to achieve. And I think a little bit walk in the park of the shift left will be nice to do. I think we were doing just pen testing or application security back in the days, which is do you pen test your app? Yes.
No, done. My application security program go home. Well done.
And that caused a lot of noise, a lot of pains, because we all love CVSS and will come out of a pen testing. I mean, carry on, but sorry, I needed to put up the irony sign. Maybe we can do that later.
But you got a green screen. We’ll take care of it. You can do whatever you want.
I am afraid, very afraid. But talking about the shift left, we were trying to bring security back as soon as possible and I think that has succeeded too much where we lost complete control where security was happening, if security was happening. I think security team all of a sudden lost control of where security was happening and either tried to clamp back on security tools saying every CRC pipeline shall have this 400 technology tool or completely rely on DevOps teams to do so.
But then security is still responsible of actually security on an organization they can just say is everybody responsibility. Is actually everybody responsibility, but security accountability. So the Cecilneck is on the block, and especially with the latest talk about security being on the board and security being actually accountable, especially for medical device and few other device.
I think they have scared a lot of security professionals. But I’ve seen a move towards reclamping back all the security tool and maybe destroying all the interesting and useful effort that was the blend between security and developers over the time. But then all these sorry, no, go ahead Mike, because I was going to say this fear seems to have driven like a fight or flight response from AppSec teams where we’re talking about shift left means developers, you’re suddenly responsible, we’re going to give you all these tools and go fix everything right before code gets into production.
And I think one of the problems with that statement is the fix everything. And I think that’s kind of what you’re alluding to here is that it’s great to have observability but there’s probably some better risk and maybe AppSec getting control or infosec getting control is communicating risk to these teams better. I do agree.
I think it’s getting back in control, first of all of what are the application that we’re trying to protect how they are structured but also getting the buy in? Because just identifying problems doesn’t mean that the problem get fixed if you don’t get the buy in from the business, if you don’t get the understanding of other than spending money to actually buy your own shiny star asked tool across the pipeline, actually you need to make some work to actually fix those things. And those work actually can be quite daunting. Readers lock for J readers as any particular library that you want to upgrade, regression testing, discovery of things that somebody built 400 years ago and all of a sudden we are all using but we have absolutely no idea where it came from and so on.
You’re mentioning asset management. Yes, we’re going to come back to asset management. We are going to say yeah, speaking of things that are 400 years old, that’s one of the basics of start with an asset inventory.
It’s kind of when people say with threat modeling, start with a dataflow diagram. That’s nice to say, but no one has that DFD. No one has a really good asset inventory, do they? No, I think it’s incremental approach.
It’s the incremental approach that you can do but without. Let’s not forget what’s important like asset management incremental approach around maturity and maybe we can reconnect with the vulnerability management framework and we’re trying to exactly do with the framework. But back on the topic of shift left and shift right, we’re still trying to push tool either on the pen testing side of it or in the operational side of it or left as soon as we write code.
And those two approach are both good. But then we forget the fact that they all need to be reported up and centralized up because having 400 backtracking reports that nobody has visibility on. And I think Tanya Janka spoke about this in RSA completely leave you vulnerable and lost from a development perspective, from a security perspective.
And in security are accountable and developer are responsible developer just search what do I need to do in the next sprint? In the next couple of sprint, like fixing everything, fixing X, Y and Z, fixing things that are in an SLA and you know my love for SLA. But without the support of the business, it’s impossible to go ahead and you’re not going to go to any business owner and talk. Look, I have Lock Vojay in this dependency that is bored in this kind of three or four call of this dependency.
And by the way, this application has 400 of this and we have 400 critical what shall I do? And the business owner says, I don’t know, this is a bunch of money, just go and spend it on some other tools. I have no idea what you just told me so I’m going to ignore you and I’m going to nod. We need to communicate more into risk.
So you’ve described shift left, shift right. I like the idea of shifting up and we’ll get to maybe whatever it looks like for shift down too. But a lot of it sounds like security is expanding.
For example, this is the big bang of security that isn’t just going to one place because you’re talking about responsibility as well as accountability but there’s got to be a communication as well. So talking to the business owner, talking skipping all the way up to the board level, you’re not talking about the volume of vulnerabilities, I don’t think. You’re not talking about the SLA, you’re talking about something else.
But tell us what that something else? What’s a healthy conversation for that something else? That’s a really good question, Mike. And I think we got used to the fact that boards start understanding slide dependest or regulations, started putting very technical terms like fixing CVSS or fixing specific time frame. And they both start using those terms like talking with the CESO and saying, have we done the Pen test for this year? Or are we fixing specific vulnerabilities in this SLA? And we kind of go reluctant and relaxed on the fact that we can use specific metric or specific terms across the board and across the business.
But actually the majority of the business owner, they have a pot of money and they need to decide what is the risk that I’m mitigating today? Is the risk of not going to production, is the risk of losing competitive advantage towards my peers? And do I spend the amount of development cycle in developing something new, experimenting with something else or fixing security? And if we keep on talking about vulnerability, vulnerability are first of all, uncontextualized. Second of all, they don’t have an indication of probability of something to happen and they are not risk. A CVSS is an embryonic vulnerability that is happening at some stage and I’m always a little bit conflicted because there is the whole debate of fixing everything as soon as it jumps up whenever a piece of code is being produced and that has I think some advantages on disadvantage.
Some stuff you can immediately identify and fix it immediately. It shouldn’t even be recorded. Fix it there then happy days.
That’s what we called immediate fix or immediate triage. But then there is other 80% of other things that you detect offline or you detect or you can’t fix it immediately and they become part of a backlog of fixes that need to be addressed and all of that bulk of things need to be really expressed in terms of risk. And the risk is how likely something to get to manifest and that is driven by the likelihood of attack pattern of specific CVE or CVSS that is probably three to 4% of the 100% that we have right now of the total number where it is located.
If it’s externally facing, there is a likelihood of something to get exploited versus a very internally facing application and then how impactful is a specific application. And I’ll tell you a joke, when I was back in the days talking with one of my business owner, I said security keep on saying SLA but I have a payment gateway and I have enough that just my internal development team use it for me. Those should have different time but they keep on nagging at me that SLA is late on both of them.
And I keep on saying well, my development team is actually focused on actually upgrading the library on this very important piece of tech and sometimes we have beneficial conversation with the security team and development team and the business owner. But sometimes it’s so blind and we so stick to this traditional method because we don’t use risk. So my message to the folk use risk because it’s very simple to use and we have the metrics out there and we wrote extensively about data.
Go ahead diamonds because we’ve been francis and I’ve talked a lot about risk last few weeks, back and forth. When you go out, I think what be interesting for our listeners for a little bit is to when you talk about risk, right, I think it’s a right path to go. But how does that those business folk people, they think about risk all day long but when you go to them with this conversation of actually trying to reframe it like this, what type of response are you getting to that? I get the eyes lighting up because first of all, you have a technical person that goes and talk to a business person and finally talk in terms of risk.
Because the beauty of it is that SLA you can’t debate about, SLA you can fix, you can create a waiver, you can create an exceptions and that’s the best you can probably do with an SLA. But it’s flat and is across all the vulnerability that you have and is a battle that you will never win and you will get to exhaustion very quickly. And don’t let me even started on SLA to actually break pipeline because that’s a whole topic that I hate or I love to talk about the hate that I have for those but if you’re a business folk and you can say, well, the risk for me are not going to production tomorrow with this set of features versus fixing all these bloody vulnerabilities is actually much higher.
And there might be a chance that somebody will exploit you. But what is the chance that the business will shut down if you don’t release a feature or you don’t release a fix or you lose a contract or you lose a license? There are tons of consequences that are out there that are nuances and what we tend to use is metrics that are black and white while the business operating in shade of grace and the risk enable to express this shade of grace and the risk tolerance and the level of risk that the business want to operate. And the nicest part as well, John is that not every business want to operate at the same level.
Like some business are very happy to operate in a very highly risk environment. Some others, like critical national infrastructure are heavily regulated to operate at a zero tolerance level because there are life at stake. Like in a hospital, if you have critical vulnerability on your heart rate monitor and I still don’t know what we have Windows Vista on heart rate monitor, but that’s a different conversation.
If those get exploited or run somewhere we’ve seen several times in the last year a hospital stops. So the risk tolerance of a hospital versus a risk tolerance of, I don’t know, a kiosk that has Windows Seven tablets or any other tablets, the risk level of those organizations are very different. A lot of this then it seems that SLA time is something easy to measure.
I appreciate time, as you can see from my TARDIS top hat, of course, but measuring volume of volumes, how many did we find, how many did we fix? Those things are easy to measure. It sounds like you’re describing much more of a maturity model now and bringing risk. I don’t disagree but I do see it as a little bit harder to perhaps make subjective or there’s perhaps more art than science in risk calculations.
When you discuss risk with these orgs or find out how they’re presenting risk, how do you approach that? Or what have been some of the constructive conversations you’ve seen around that? Let’s start with the destructive conversation of like we don’t know how to measure anything. So we’ll express gut feeling because gut feeling is better than basic math. And we seems to fight a lot of this where people are really better at expressing risk or identifying risk or acting on risk.
Like we are probably wrong 80 or 90% of the time if we do a gut feeling assessment of risk rather than using math. And there is a psychological aspect of, especially right now being redundant, or that somebody else could do my job better than me, or a math formula could do my job better than me. So there is a fear factor of automatic calculation of risk versus human actually judging what is the risk.
So there is debt, reluctance and as everything security is about people, culture and a change and a transformation that needs to happen in the people and culture. So, going back to your question, that’s why we created the Vulnerability Management Maturity Framework. Because as a security professional, we tend to say we need to do risk at the highest level with the most data rich sets and measuring everything and seeing everything.
Fix all the things. Fix them all now. Correct.
But how do we get there? We want to go to the moon but we don’t even have start building the rocket so start step by step and that’s I think the approach of a risk based approach and risk is not hard to calculate. You just need to start with a very basic set of information that you probably already have. Like how are application created together, how do you glue system together, how do you assign a probability of exploitation? And there is plenty of data sets out there that tells you full specific vulnerability, how likely is a category of vulnerability or a specific vulnerability? And I want to do a shout out to a fantastic project that is EPSs that is operating around there.
So there is data out there to calculate how likely something to happen. How bad is something to happen? That is expressed by CBSs or CWSS. So we have those information and the impact on an organization and you know what, that’s risk so it wasn’t that hard to calculate.
We’ll provide your contact information at the end so everybody can do Frank as a service for calculating risk. I love Frank as a service. Let me be there’s context yes, perfect.
There is context that has to get added on here and I think that’s kind of what you’re pointing out is that risk changes based on is this perhaps not internal, not just connected to the internet? Not connected to the internet because we live in the world. I’ll throw out my buzzword for the day, the idea of zero trust or we have maybe established perimeters but if there is an compromised internal service that could spread through other internal services if there’s a compromised developer endpoint that now potentially has access to internal services. So there are risks that are internal and I think where I’m trying to go with that is figuring out what are some strategies that come out of a vulneragement framework to be able to get to a higher maturity level to shift from one level to another is to use our other word of the day.
That’s a very good point, Mike. I think when we discuss about risk, usually that’s the knee jerk reaction we receive. We hear people saying, oh, I need this, data set this, data set this, and all of a sudden the mental reaction is oh my God, it’s so complicated, they will need ages for us to actually even start.
So let’s just use CVSS and use knee jerk reaction and let’s make developer responsible of this. Let’s go back in the old way. So that’s why we created the vulnerability management framework and divided in different area from discovery to prioritization to aggregation to resolution process procedures and action and measurement.
Because really as a nuance like running a vulnerability management program, and I refer to vulnerabilities in the broader spectrum from software to cloud to OS to traditional patching and infrastructure management because it’s all the same process. The people that operate it, we might have some slight nuances metrics differences, but the process is all the same and you don’t need to be a super expert to start. You could start by in the discovery section, for example, scanning for your code or scanning for your operating system and that’s good enough for certain organization, but you might be lacking completely the concept of risk.
So the concept of aggregation of different pieces together and the ability to actually say this blob of assets and backing asset management equal this level of criticality. And that can be even a spreadsheet in the very basic form with some metadata and some queries. I know everybody hates the spreadsheet, but any security company needs to find a fight against a spreadsheet or a tableau.
Yes. How many vendors on RSA could be replaced by a spreadsheet? No, I was literally going to say the same thing. I’m going to pick on a cure for a second.
As you’ve been coming into application security at the industry, does this make it easier and make more sense to you about how to sort of tackle some of the things you work on day in, day out, thinking about from a risk point of view or putting a framework around it? Yeah, actually I really like what you said earlier, Francesco, that vulnerabilities do not equal risk. And a light bulb went off on my head of like oh shit, he’s right. So thinking of things like being able to calculate this in a much more like pragmatic way seems that that would really help.
And the reason I say this is because in my experience so far, you start a job, you start on an app SEC team, and maybe the first thing you want to do is run zap against your app and be like, oh, my God, look at these reports. There’s so many vulnerabilities. We have to fix all these right now.
And it can get really bogged down really quickly because trying to communicate vulnerabilities to software engineers is maybe not as exciting as communicating risk to software engineers. So I feel like we’re talking about how we can talk to these business people with risk and they really enjoy that conversation. I think we could also bring that to the software engineers as well as opposed to just being like hey, fix this thing, fix this buffer overflow or whatever the heck is the problem at this point.
But we can say, hey, if we don’t fix X problem by X date, the feature that you’re working really hard on to bring y business value is actually going to maybe get taken down. So we need to figure this out. And I think that that would make for much more fruitful and interesting conversations along the developer team.
I actually had a question for you as well. I agree. And actually it’s something that I always use, like trying to explain a risk context in a very simplified way to developers.
But sometimes developer don’t care and they shouldn’t. And I might be controversial here, but a developer cares about what do I need to hit to get to my OKR, to get to my profile, to not look bad with my boss? And that is the number of features that needs to be developed and the number of things that need to be fixed and the number of bugs that needs to be eliminated. And we might sometime romanticize a lot what is the developer life, but actually it’s a lot of grinding and a lot of boring stuff.
And I’m a software developer by trade originally, so I used to deal with just hit these things by X Date period, without any context, without any conversation and sometimes that’s what we forget. A developer will never have a glorified conversation with a product owner. That’s probably more likely that a security engineers will talk with a set of product owner and say you need to reach this risk level, you need to fix this amount of vulnerability.
And then the debate goes to the line of business owner or other people in the organization where you get that information rich or high level conversation, that where target can get agreed and developer can execute on the back of those targets. But the vast majority of developers just want to know what they need to fix, where do they need to fix it, and what they need to look at for the next couple of sprints. And if they have that right, and if they have that muscle because it’s a boring muscle, then they can get maybe more free time or more brain time to actually start discussing with the security person or tailoring, maybe the Zap profile because it generates too many bone.
Or how we can customize a specific SAS profile because it generates too many false positive. The achievement on certain targets generate interesting and impactful conversation because you try to find different way to actually achieving those targets. I’m sorry to be confused.
I think aren’t you also describing a bit of the maturity level aspect of the development team or the developers? Because there may be the initial junior developer who does have that attitude or says I have to prioritize this work, just show me relative priority of this vault. Does it go above the threshold for this brand or below the threshold? That’s that whereas more senior developers will be looking at this and they still care about software quality, I think we can make, I think, support a good argument that security is a major aspect of software quality resilience. And maybe those more senior developers are looking this not as like a bug ops approach where, okay, we have to fix this vault, this new vault, this new vault, this new vault.
It’s more of why are we getting the same category, the same class of vault so many times? Maybe we should step back or set aside some time to do something else with our architecture, make it harder for this class to be introduced in general. So I think we’re talking about shifting, but we’re also talking about maturity levels and that’s where I see that conversation being more nuanced with developers depending on who the developers you’re talking to. I do agree, but does a developer have time most of the time to have this conversation? Like if it comes to crunch time, we will default back to basic human instinct, that is what do I need to do to actually keep my job? And if we have those OKR and those security metrics and those software metrics ingrained, regardless when it comes to crunch time or in relaxed time and right now we are really in crunch time because software teams are shrinking and software engineering teams are shrinking and security engineering team are shrinking.
And I fear that in those crunch time, if you don’t have KPI that says x amount of story point or being at specific risk level for an organization, you completely lose the ability to actually be heard from the developer because the Security Champion program is all good and done up until there is crunch time and security get forgotten. And if you have those OKR ingrained, that’s the only way we can defend. We can put or accodify an objective that is human nature to hit and make sure that security is respected.
As we’re leaning on then the risk level, does that shift more of the responsibility onto the AppSec team now to translate the risk from all of these scanners into their environment? Are there tooling or spreadsheets, for lack of a better word here that can help with this approach? Because now it does sound like rather than look at individual CVSS scores, we have to triage every single vaughn which I think in spirit I like the idea, but that sounds like a scalability nightmare that. Sounds pretty tough. Well, the good news is that you can automate a lot of this stuff.
Like you can discuss with a specific you can discuss with specific developer team and say, include a YAML file in every repo that describe your application ID. And here you go, you get asset management completely done and maybe a GitHub action ID that sends all the artifacts with that application ID in a central point. And that’s the aggregation part of the vulnerability management framework.
And then having all these information centralized, then we can deploy big data insights that we know how to do. It like Google Analytics styles to actually understand what are the common error and issue that we do. What are the common software category, what is the common library? We can move from engineers being used as a sledgehammer, as engineers being used as a scalper.
So we go and surgically remove or surgically upgrade a library. Or if you have a consistent error on authentication, then maybe it’s worth to actually write a central library for authentication to interface with Active Directory, where 90% of everybody getting hacked is because they interact directly with LDAP in Active Directory. And those are just some of the example.
By looking at insights and having the data centralized and having that famous data lake really can bring the value of an AbSec team. And it doesn’t bog it down to actually triage in day in and day out. Don’t get me wrong, triaging day in and day out is important and needs to be there because it creates the empathy of a security engineering team with developer sitting on a sprint, planning, doing exercise to actually identifying an issue and a vulnerability needs to be in there.
But I don’t want my AbSec team and I had an Absect team where we had people burning out every three months and resigning because of the scale of the problem. I don’t want to see that anymore. I don’t want to see anywhere.
And that’s my mission to the world. That’s why we created Phoenix and vulnerability management framework to actually change the status quo because I don’t want to see any more upset people burning out. And if we keep on rolling the square wheel, I don’t know if you saw the meme that is constantly like we’re too busy pushing a square wheel to actually innovating and creating a circle wheel and actually being smart about it.
We’re too busy doing the same thing over and over and actually innovating. And maybe right now the innovation is AI is a part of innovation that we all focus. And you saw my run the other day when I said, well, let’s focus back on the innovation that actually matters.
Francesco, I have a question for you on that. If you had one small step toward innovation that you would have AbSec teams do, what would that small step toward innovation be? That’s a good question. That’s a good load of question.
I think centralizing the data at least that from a vulnerability scanner perspective and applying prioritization at scale at least solved at scale in an automated way quickly the problem or converting from CVSS into risk and using the open source data that we have available to actually prioritize the vulnerability and having them in one single place enable us to do that at scale and then deciding what’s going to be the next step. For me, the next logical step is creating an asset register. And you can do that by reverse engineering the vulnerability information that you have.
That’s a very easy way to actually say, okay, maybe we don’t have a complete asset register, but if I aggregate my security Hub, my GitHub, my Azure Sentinel, my Copilot, and all the other scanner solutions that I have, all of a sudden I have an 80% accurate asset register, automated especially too. I make the joke all the time too. They’re like Azure AWS, they know how to bill you for all of your assets.
So they have a pretty good idea of what’s in your cloud. So ideally you should have that same visibility as well. It’s when you get outside the cloud that perhaps it gets harder.
You can do that from Vulnerabilities. You can do that from Vulnerabilities. It’s complicated to connect to all the service.
For example, on AWS. And being in AWS, I know it bloody way because we used to develop things in a very atomic way. So all the product in AWS are disjoint for a reason because they were created as an individual project and everybody has an API because there was the rule number two that we used to create new product.
But the problem is it’s all disjunct. So you need to query. 178 different APIs will even have an idea of what asset do you have and the number of products are actually growing.
Azure and AWS nowadays have created a good way to query for asset management in a better way. But those APIs are changing all the time. And as security engineers, we’re not very good at development.
So even as fresh we should be. I think that’s one of the things is that we have, I’m going to use a big word today, bifurcation of AppSec into the governance angle of we’re checking your SLA, or perhaps more mature as you’ve been describing, where we’re measuring risk, we’re communicating risk. And then the other path is that engineering that’s building guardrails, which I think kind of you were alluding to in the sense of interacting with Active Directory or just building a controlled authentication service or another type of service that gets rid of a category of vulnerability.
I want to throw you a question though. How do you make the case to actually spend time on developing a library? Because it’s a business case and you need to have an AI. How do you measure that? You can’t just simply come up as a security man, we want to create guardrails what is the ROI? But if you have good measurement, you can say by creating this security default or disc guardrail, call it whatever you want.
We remediated a category of issues. So we remove X amount by spending Y. That’s a business case that will give you so much more development and engineering time because that’s where I was going before as a security engineers.
We’re not developer, and there is very rare, we’re very few that can actually write code. And my code is terrible right now, so I don’t want to even come close to my piece of code. But that’s the reality of things like we have very little security engineers that actually write code, and even the one that do, they’re not developer by trade because we need to know a lot of stuff.
So in order to make the case and build this security default, we need collaboration and we need to borrow developers or have developers in our security function. And in order to do that, it’s removing developer from top line revenue generating application. So we need to make the case for security with ROI like everybody else does.
And if we don’t have measurement and metrics, we can’t demonstrate the value that we bring into an organization. I think for me, I look at it, there’s an easy path. If we have a bug bounty program and then we’re getting lots of particular types of reports coming in, that’s an easy path because we can say, look, we’re paying $500, $5,000 a pop for these volms.
Why do we keep getting subdomain takeovers? Just to use an example or cross site scripting that starts to lead into then? Well, we could either do our I’m trying to coin the new term bug ops as an anti pattern. We can try to just fix all these bug after bug after bug, or we can shift that conversation between the appsect team and developers away from, here’s what the threat model is for this, here’s what the risk level is, here’s the deep dive into the, whatever some fancy project name, or we can have that conversation. B, what if we accepted this risk and we didn’t fix all the volumes and instead we did Project A, where Project A is something like those.
Guardrails now, obviously I’m being a bit vague in hand waving, but I like that change in conversation. And I’m curious if you see it’s been viable to have a conversation where that leads off with we’re not going to fix everything, we’re going to let these vaults smolder. And is that purely a risk or do we need to have risk be a large part of that conversation, or can we take other ways of approaching that? That’s a good question, Mike.
I think there is a knee jerk reaction that traditionally when you start saying, don’t fix vulnerability, people look at me like a madman and there’s been a lot of debate, especially of recently, of patching. Fixing vulnerability and patching is super important, but fixing the vulnerability that matters most is even more important. Er, and I just corniated the term, I guess it all matter about the story that you tell, like in a quote of Dustin Lear and few other upset folks, we are storyteller as upset people.
We are storyteller and we are sellers. And if you don’t tell a good story and if you don’t have the data to actually tell that story, your story will fail to convince the business that that’s the case to do. And as you say, Mike, maybe if you have a category of bugs, you don’t know if today or tomorrow or yesterday those bugs were there and not there.
Or maybe they’ve been fined by a security scanner that we have internally and we spent, I don’t know, ten grand on bug Bounting where we already knew those category of issue were already there. So we actually wasted time. But if you correlate, like it’s a data problem.
If you correlate all these data set, you can tell a very powerful story together with telling the risk story that I always hammer. So a lot of the stuff that we are facing right now is maybe we have very qualitative and very pervasive security scanner. So we have a sea of data, but no way to make sense of all this data.
And what I always say is we have a sea of data, but data is not inside. Data doesn’t tell you what to do and where you’re doing wrong, if you’re doing something wrong, but inside does like extracting inside a lot that data is what we need to do. So maybe we need data scientists instead of software development in our security team or AI.
Yeah, we need to shift onto we’re almost out of direction, so I don’t know which direction we’re shifting into data science, but I think that makes sense because I was going to ask, how do you equip we’ve got a cure with us? How do you equip Akira to talk to tell that story with developers she’s doing every day? A data scientist is a glorified spreadsheet. I started with glorified spreadsheet to tell a story and they hate mail now. I know.
And it’s just pie charts. Yeah, that’s all it is. Yeah, but that tells a story.
Like a trending diagram that tells this category of issue has been happening all the time. It’s just four query on five security tools that we have a spreadsheet that captures stuff on an amount of time. And then when you break the spreadsheet, you create a database and then you start making the case of maybe a data scientist team or a security team.
You start evolving that. And that’s why I created the vulnerability management framework, because you start aggregating a set of data or prioritizing a set of data, but you don’t start on the moon. You start with really basic stuff so that in five or six projects, you demonstrate the value, and there you get the buy in from the business to actually do more, and maybe you can borrow more developers, and maybe you can create more complex system.
It’s an evolution, and if you try to boil the ocean, you end up probably disappointed. I had a more witty way to close that sentence, but it kind of well, I don’t know. So maybe Akira not to put you on the spot immediately, but now you’ve listened to this, and you’ve got a story to tell.
What are some things that you would do? Do you feel equipped, or are you looking for one more thing in this maturity framework or one more of these data sets that would help you fill in that story? The thing that I’m still wondering about is how, you know you’re ready to move from one segment of maturity to the next one. I want to talk about that a little bit. That is a really good question that we’re still debating.
I think we’re converting. Like, each set of maturity levels have steps and have actions, and what we’re debating is you need to complete all your quest to move to the next level and to upgrade your character. And jokes aside, I’m a massive LPG nerd, so I love to complete every and all the quests, but actually, a lot of organizations don’t.
Like, even if you do one or two, you’re good enough. And I think we want to be vague with the framework and don’t want to mandate it, because as soon as you go down the rabbit hole and say, you need to complete all of this to then move to the next step, you start becoming a very restrictive way to you start removing the intelligence out of people. And I like to say, as a security folks, we’re super intelligent, but also as ADHD people, we get lost all across the board.
So having some guardrails that also give you some wiggly room to say, okay, maybe I’ll aggregate vulnerability, but I don’t do Risk right now, and maybe tomorrow I’ll do Risk, and I go to the next step. Like, if you get comfortable to use specific things in one of the box of the framework for one specific category, then you start defining your roadmap to the nexte on. Okay.
We are maturity. X how do we get a maturity y or we stay a Maturity X because we still haven’t covered the whole organization, or we haven’t covered a critical asset, or you can cut the data and the maturity level in the way you want, but it’s up to you to define how far you want to be to a maturity level. And we have organization that use this and say, I want to be a Maturity Level five because I’m a bank and because I need to defend against every single nation state.
And then we have retail organization that says I’m happily living to have some level of risk, some level of even SLAs are fine for me and that’s fine. So I think the other thing that we’re running out of right now is time, unfortunately. But John, your level of risk, we want to close this out with maybe a last question for Francesca.
How far can you move up the maturity model and still use Excel? No. So one of the things that’s been on my mind as we’ve been talking through here is you were slightly sort of deriving the concept of SLA and like poo pooing and blah, blah, blah. It seems like in a way maybe how we are measuring SLA.
When we say SLA, that’s a very sort of big broad paintbrush which we’re stroking with, at least in my mind, it seems like that should be maybe a little more instead of just throwing it out but actually focusing it down and saying like when I’m talking about SLA, I’m talking about this particular thing. Would that sort of help part of reframe that conversation? Yes and no. I think I’m extremely against SLA or extremely aggressive against SLA because we seems to have stacked our security brain in something that was really quick and easy to measure and there is nothing wrong with that.
But it became the bible of every security policy and every SDLC policy that we brought up. Fix SLA, X, Y and Z, break CI, CD pipeline, if you have these categories of this SLA, we never went beyond that nuances because everything above that is slightly more complicated or require a little bit of more brain power or we didn’t have a framework before that and now we do. I think to reply to your question, John, I’m not against SLA, but SLA is a data point that you can use to create a story.
SLA from Discovery time tells you a story of how old this vulnerability has been existing. But your risk level might never hit that particular vulnerability. And that’s exactly fine.
And then SLA for how long this ticket has been in the queue, tells you a very different story than how long this vulnerability has existed. Maybe you have too many tickets in your queuing system, that vulnerability keeps on piling up. Why we don’t get to those specific vulnerability or closure rate is still an SLA, or a metrics closure rate of vulnerability.
How quickly are you closing vulnerability? That tells you another story. The famous meantime to resolution, meantime to open, tells you a different story. I think for me, those are all data point that tells you a story.
And when you put them together, together with risk, you create a very controlled and powerful way. And with Nissu around the block and with more regulation coming from the US and NIST two is the equivalent of the Cybersecurity Act from the US. Here in Europe.
I think those two are driving really into the must shield or be much more in control of your program and no auditors will ever come to you if you’re in control. And if you can tell a story of like, yeah, my risk tolerance is here, I know that this risk level is here. I have risk exception for these vulnerabilities and they will never tell you you shall fix vulnerability within SLA.
But if you use SLA, it will always tell you you’re out of compliance, you’re out of SLA, you have critical vulnerability, you shall be punished. So using risk and intimate better way to control I was going to say feeling control. We’re running up again.
We passed our SLA. Francesco, our story does have to come to an end, but we’ve obviously enjoyed our time with you and you’re going to have to come back because I don’t think we’re finished with this conversation. Clearly.
Before we let you go, we do ask all of our guests to describe AppSec in three words. So your SLA is limited on time and number at the moment. So what is AppSec in three words to you? I think it’s beautiful, chaotic and a sales process.
We’re going to have to refine those into three, but that sounds pretty good. Beautiful, chaotic and sales. Chaotic and sales.
Love it. Then where can people find out some more about the work you’ve been about these frameworks or what you’ve been doing? Yeah, so that’s a really good question. So for the vulnerability management framework, we have a Slack channel, that is vulnerability management SIG on Oasp.
And if you’re not on Oasp, www.oasp.org. There is a Slack community out there where we debate and discuss around everything upsec there are different channels. We publish the vulnerability management framework and the Phoenix Security vulnerabilitymanagementframwork and I regularly talk about this and we’re actually creating a more structured approach on the vulnerability management framework by including the vulnerability management framework as part of the DSOM.
That is what Timo created as a DevSecOps maturity measurement. So you will be part of that and as soon as we get together to actually converting a lot of the stuff into JSON. So I have SLA around my time as well, unfortunately.
Indeed. So join the Slack channel, continue the conversation there with Francesco. And we want to say thank you for joining us.
Thank you, Mike. Thank you, John. Thank you.
Akira was a pleasure as always to speak. Also want to thank Akira and John. And as you know, in this week, in place of the new segment, we’ll be running two interviews from last week’s RSA conference.
Thank you for joining us. Please hit subscribe and hit that. Please subscribe.
Hit that like button. Check out the show notes. And speaking of good conversation collaborations, check out Severed by New Arcades and Droid.
Bishop. Stick around for the RSA interview segment coming up. We’ll see you next time on Application security weekly.