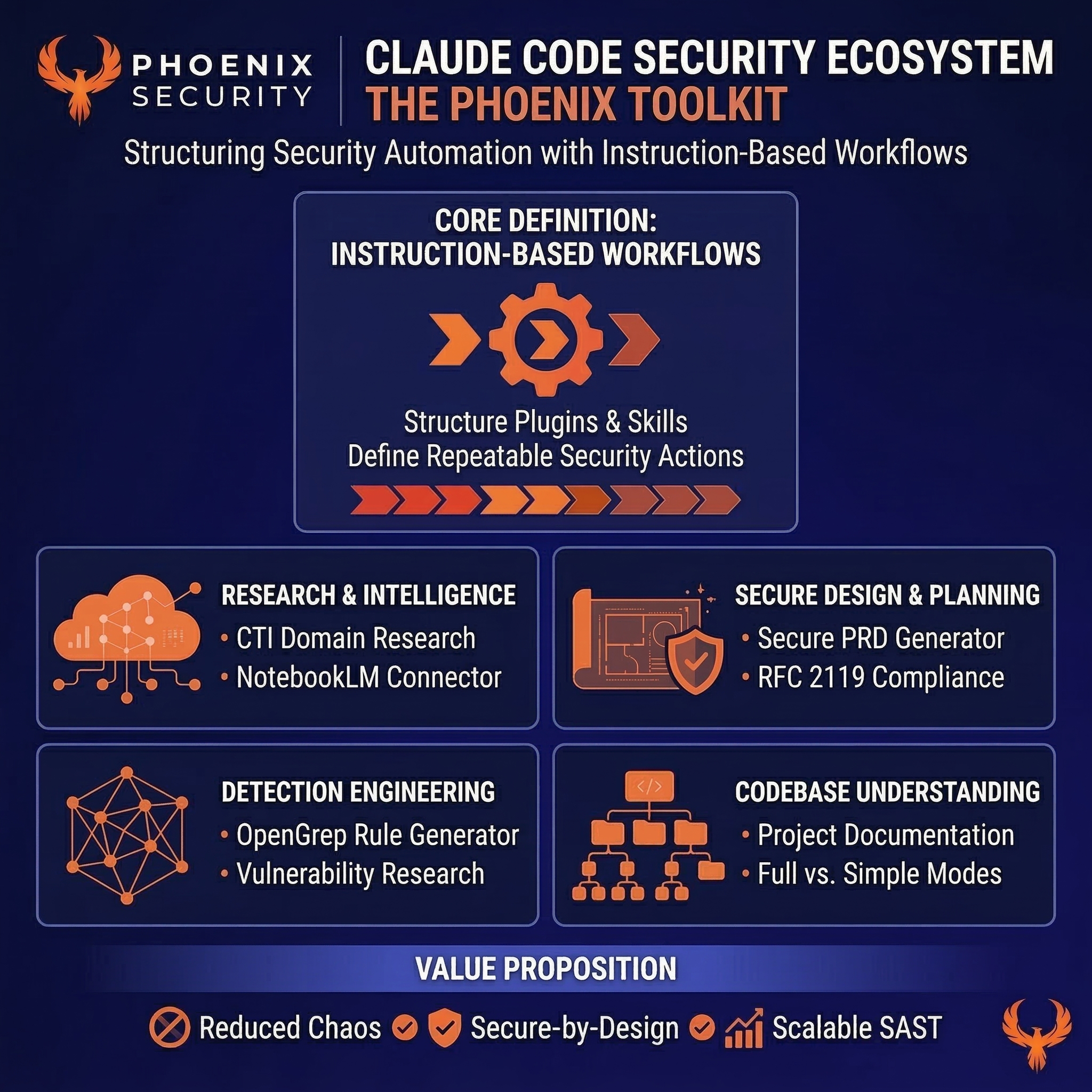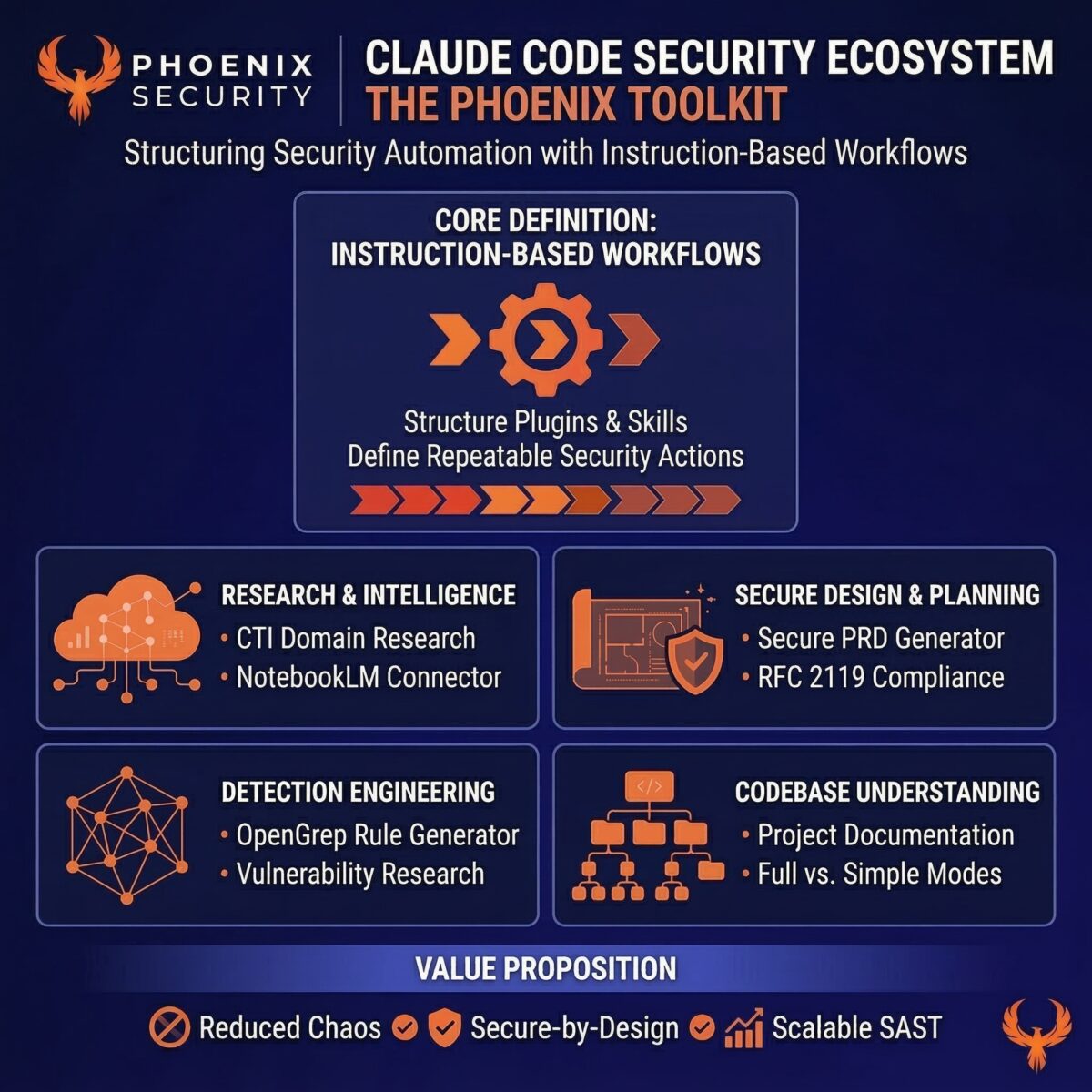
Phoenix Security has open-sourced a set of Claude Code skills that give security engineers and researchers a production-tested AI toolkit covering threat intelligence, vulnerability detection, secure product specification, and codebase understanding, with the practitioner staying in control throughout.
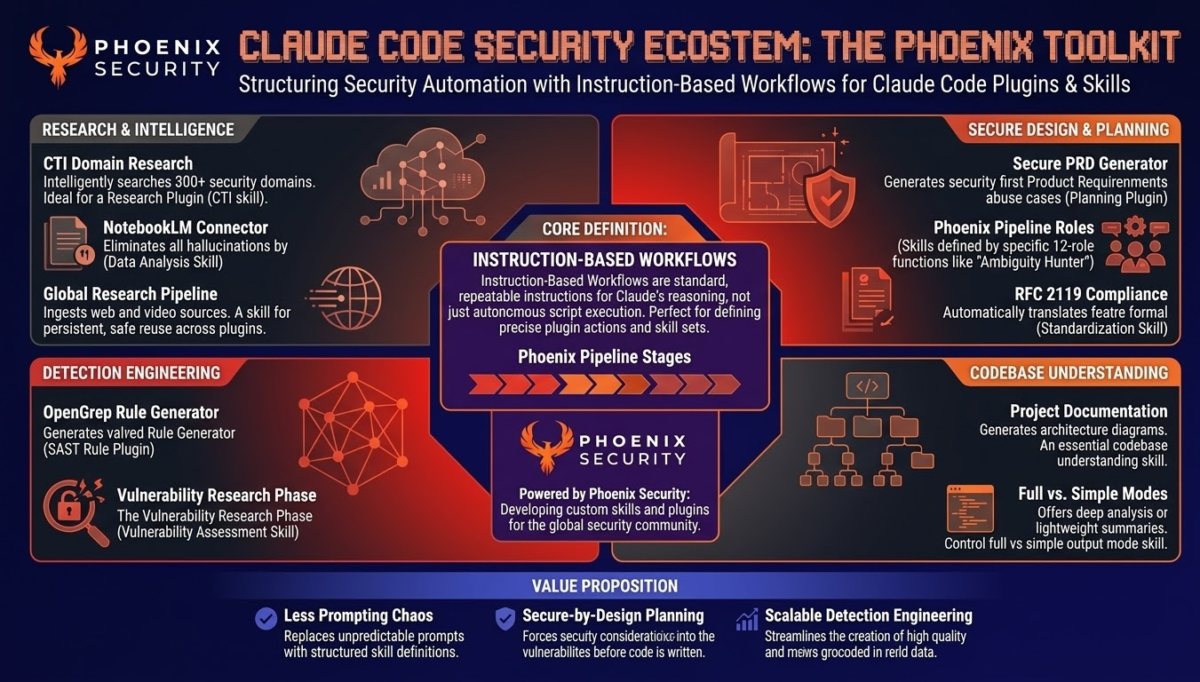
Key Takeaways:
- The skills are free, open-source, and available at https://github.com/Security-Phoenix-demo/security-skills-claude-code — installable via the Claude Marketplace or directly into Claude Code / Cursor
- CTI Domain Search targets 595 curated security domains across four authority tiers, with automatic MITRE ATT&CK mapping and optional NotebookLM ingestion
- OpenGrep Rule Generator maps any CVE or vulnerability pattern directly to a detection rule deployable in your SAST pipeline
- The Phoenix Pipeline embeds security into product specifications before code generation begins — not as a review gate after the fact
- None of these skills operates autonomously. Each one assists a practitioner who already knows what they are looking for
1. The Problem
AI coding tools are everywhere. Most security teams are using them the same way developers do: autocomplete, explain this code, generate a function. Useful, occasionally. Sufficient for security work? Not even close.
Security engineering has specific requirements that general-purpose prompting ignores. You don’t just want a rule that detects SQL injection. You want a rule that detects this specific injection pattern in this specific framework based on this CVE, mapped to MITRE ATT&CK T1190, verified against real exploitation evidence from CISA KEV and EPSS data. That requires structured, context-rich workflows — not a chat window.
The Phoenix Security team has been running on Claude Code and Cursor for internal work: CTI research, vulnerability detection engineering, threat-modeled product requirements, and codebase reverse engineering. Over time, these workflows became skills: reusable, structured instruction sets that activate within the Claude Code environment and produce practitioner-grade outputs.
We’re open-sourcing them now because they work, and because the security community builds faster when it shares tools rather than rebuilding them from scratch.
2. Technical Analysis: What Each Skill Actually Does
NotebookLM Connector and the Global Research Pipeline
Security research is a volume problem before it’s an analysis problem. A researcher investigating a CVE or threat actor needs to pull from dozens of sources: CISA, NVD, vendor blogs, DFIR reports, and community analysis. Doing that manually in a chat window produces shallow, unsourced summaries.
The NotebookLM Connector bridges Claude Code and Google NotebookLM. The Global Research Pipeline does the upstream work: multi-source web search, structured collection, and automatic ingestion into a NotebookLM notebook where the material becomes queryable with citations.
The practical result: a researcher can say “research CVE-2024-21762 and push to NotebookLM” and get a citation-backed brief they can actually interrogate, not a paragraph of hedged summary. An AI that shows you its sources is more useful than one that paraphrases them.
CTI Domain Search
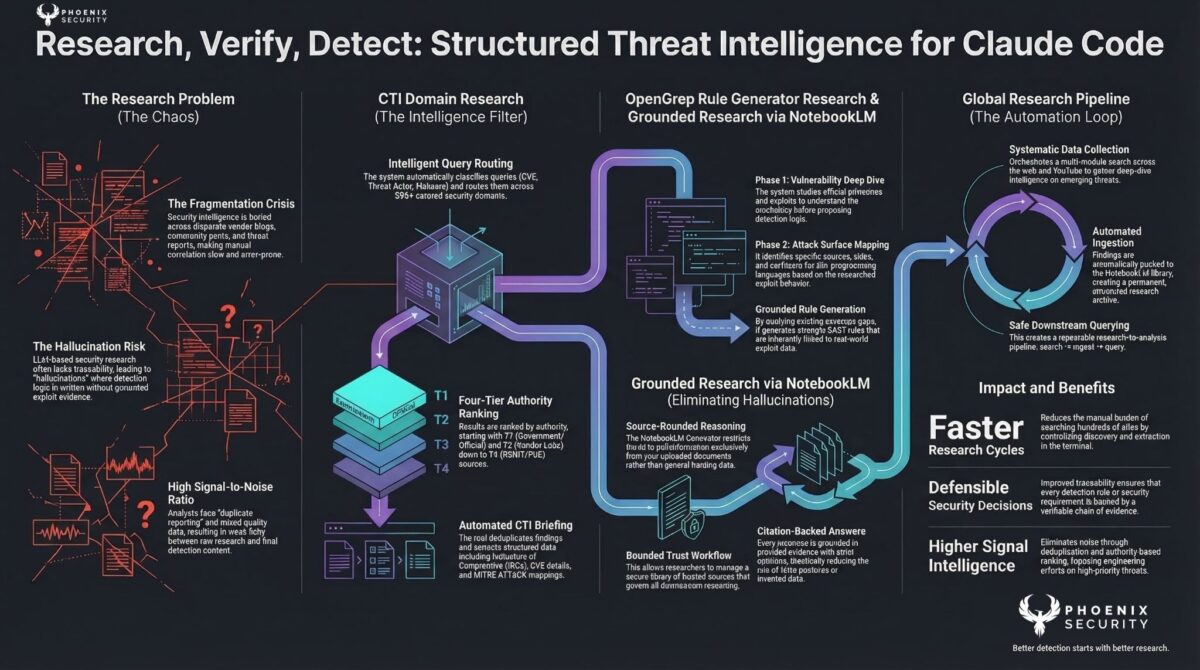
The CTI Domain Search is the specialised variant of the research pipeline, built for indicators of compromise, CVE correlation, and MITRE ATT&CK mapping.
It searches across 595 curated security domains organised into four tiers:
- T1: CISA, NVD, MSRC, NCSC, Red Hat — authoritative and government sources
- T2: Unit42, Talos, Securelist, DFIR Report, Volexity — vendor research with named attribution
- T3: BleepingComputer, Krebs, TheRecord — news and community analysis
- T4: any.run, VulnCheck, AttackerKB, GreyNoise — OSINT and PoC repositories
A researcher working on a newly-exploited CVE can query all four tiers with recency filters, get full briefs with MITRE mapping, and push the results directly into NotebookLM. The –full flag returns detailed analysis rather than summaries. The –json flag pipes structured output to downstream tooling.
You’re not searching the open web. You’re searching sources that security practitioners have determined are actually worth reading.
Phoenix Pipeline: Security from Specification
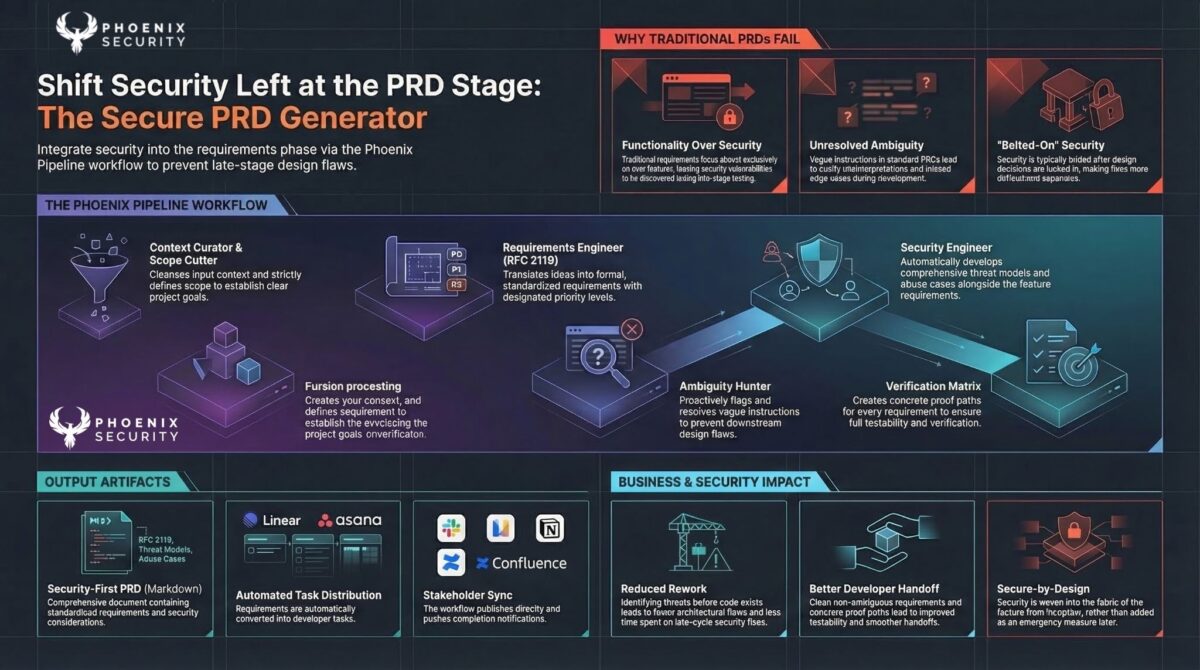
The Phoenix Pipeline is a 12-role specification system that embeds security into the product development process before code is written. It’s the skill we use internally more than any other.
The sequence: context curation → scope definition → constraint distillation → requirements engineering → ambiguity hunting → threat modeling → API contract design → verification mapping → batch planning → final gate review. Each role is a structured skill that operates on the output of the previous one.
The pipeline generates: RFC 2119 requirements with security controls, MITRE ATT&CK threat models, tenant isolation invariants, API error taxonomies, verification matrices, and Cursor-compatible delivery plans. These outputs go directly into the AI coding environment as structured context. The code generator knows the security requirements before it writes a line.
Meta-language rules, self-healing guardrails, and stack-specific security patterns are baked in at the specification stage. Vulnerabilities that are architectural in nature: broken auth, missing tenant isolation, unvalidated LLM I/O — these get addressed before they become code.
Link:
This is what the AI-Agent-Second philosophy means operationally. The agent doesn’t generate code until the context is established. Security is a design constraint, not a review gate.
Secure PRD Generator

A standalone variant of the pipeline for teams that need security-informed product requirements without running the full 12-role system. The Secure PRD Generator produces threat-modeled PRDs in a 10-stage process, with optional integrations to Confluence, Linear, Asana, Slack, Notion, and Gmail.
For teams where security engineers aren’t embedded in the specification process, this gets the threat model and security requirements into the document that developers actually read before starting work.
OpenGrep Rule Generator
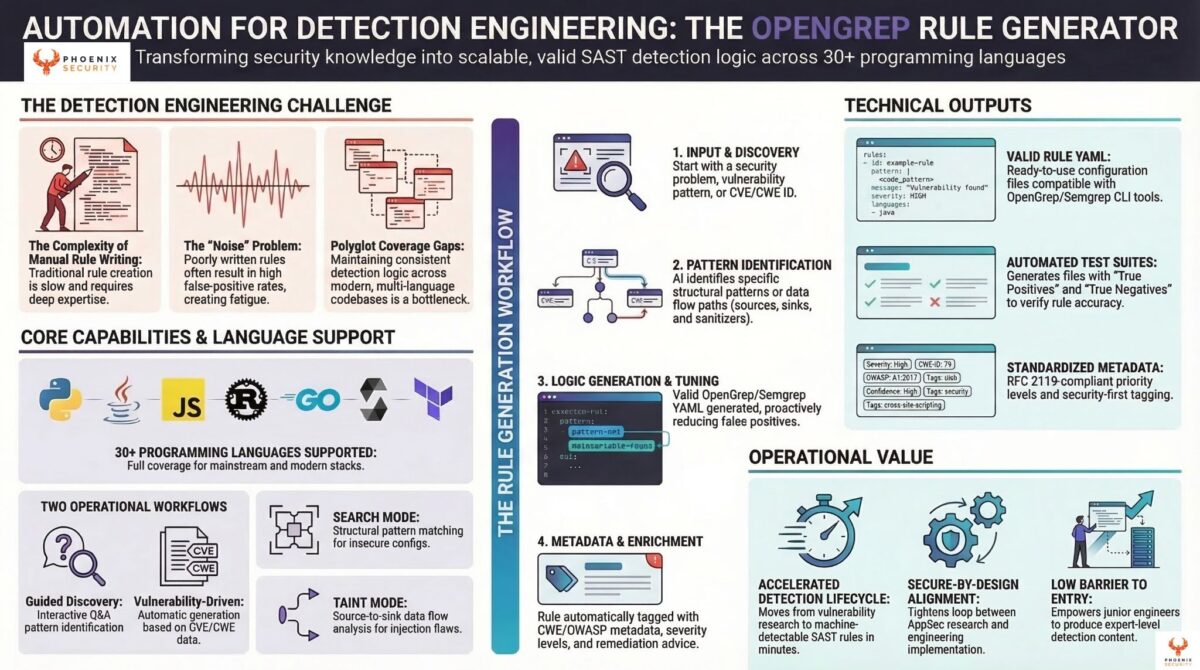
Finding a vulnerability is only useful if you can detect it at scale across your codebase. OpenGrep (a community fork of Semgrep) is the standard tool for SAST rule-based pattern detection. Writing rules for it well requires knowing both the vulnerability mechanics and the OpenGrep rule DSL.
The OpenGrep Rule Generator skill maps any vulnerability in your ecosystem to a detection rule: a CVE, a CWE, or a pattern you’ve identified. SQL injection, cross-site scripting, insecure deserialization, hardcoded credentials: the skill generates pattern-matching or taint-analysis rules for 30+ languages and frameworks. It adapts to the specific codebase context you provide.
Phoenix has been contributing to OpenGrep because programmatic detection at scale is how you close the gap between knowing a vulnerability class exists and actually catching it in production code. A researcher who understands a vulnerability should be able to codify that understanding as a rule without spending hours in rule syntax documentation.
OpenGrep Rule Generator Research
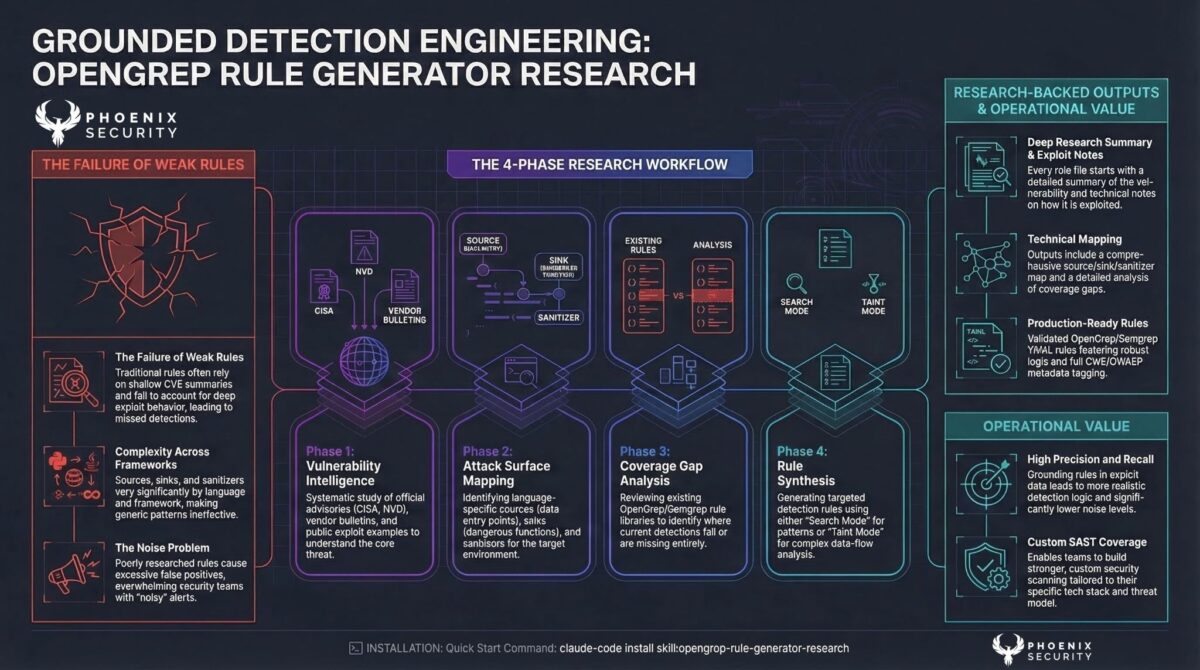
The pairing of CTI research with detection engineering. When you have the CVE ID but not the vulnerability mechanics, this skill runs the research phase first: web search, source collection, and exploitation evidence, then generates the detection rule from the research output.
The distinction matters operationally. “I know this CVE is exploited but I don’t have enough detail to write a rule” is a common position for security teams during an active advisory response. This skill bridges that gap: research the vulnerability, understand the pattern, generate the rule, and deploy it.
Full-stack Reverse Engineer
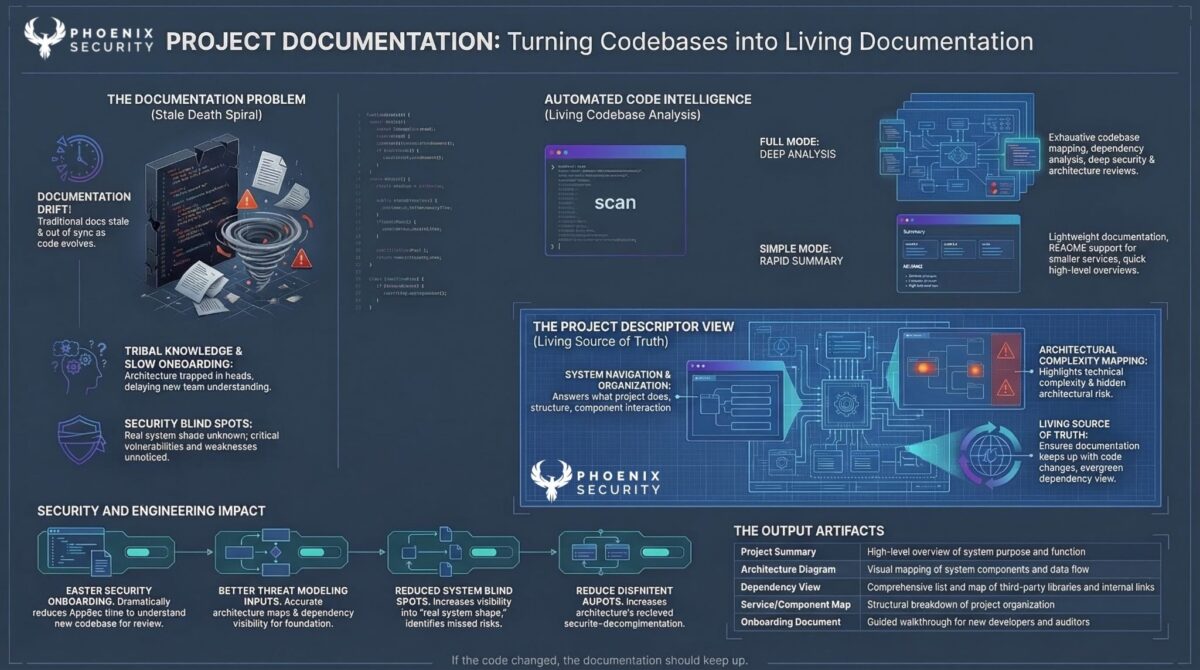
Security work often starts with a codebase you didn’t write and have no documentation for. The Fullstack Reverse Engineer skill systematically maps an unfamiliar codebase: system architecture, runtime flows, data contracts, database patterns, business rules, dependency map, C4 diagrams. It prepares a structured knowledge layer that AI coding tools can reference accurately.
This matters for two distinct use cases. First, security reviews of acquired or inherited codebases. Second, preparing a codebase so that AI coding agents generate additions that match existing patterns and security controls rather than introducing inconsistencies.
3. The Phoenix Approach: Why Open-Source This
Security teams don’t lack tools. They lack tools that fit into how security work actually happens: iterative, context-heavy, requiring specialist knowledge to evaluate outputs.
The skills we’re releasing have been used in production at Phoenix to: research CVE advisories under time pressure, generate OpenGrep rules during incident response, write threat-modeled specifications for features touching multi-tenant data, and understand inherited codebases before audit.
Each skill reflects an opinion about how AI should assist security work. The AI does not decide what matters. The practitioner decides what matters. The AI executes with structure and at speed.
None of these skills require you to trust an autonomous agent’s judgment about security. They require you to trust that the practitioner using them knows what output to expect, how to evaluate it, and when the skill has given them something worth acting on.
4. Real-World Application: What This Looks Like in Practice
During a recent vulnerability advisory response, the CTI Domain Search queried all four tiers against a newly-listed CISA KEV entry, returned exploitation evidence from T2 vendor research, and pushed the sourced brief into NotebookLM within minutes. The OpenGrep Rule Generator Research then took that brief and produced a detection rule that went into the SAST pipeline the same day.
The alternative: a security engineer spending hours manually searching vendor blogs, reading through PoC repositories, extracting the relevant pattern, and writing the rule from scratch. The skills compressed that cycle. The security engineer’s judgment (which CVE mattered, which sources to trust, whether the rule was correct) remained in the loop throughout.
The Phoenix Pipeline has changed how we write product specifications. Features that would previously have passed through an AppSec review gate at the end of development now carry threat models, auth requirements, and tenant isolation constraints from the first specification document. The security review gate still exists. It just finds fewer surprises.
5. Practical Guidance: Getting Started
Installation is via the Claude Marketplace or direct command:
# Install CTI domain research
claude-code install skill:cti-domain-research
# Install OpenGrep rule generator
claude-code install skill:opengrep-rule-generator
# Install the Phoenix Pipeline
claude-code install skill:phoenix-pipeline
All skills are available at securityphoenix.io/demo with installation guides, configuration documentation, and contributing guidelines.
For the CTI Domain Search plugin, configure a Brave Search API key (2,000 requests/month free) or SerpAPI key, set the environment variable, and restart Claude Code. The full setup takes under 10 minutes.
For the Phoenix Pipeline, start with the context curator (Role 01) when you have raw notes, tickets, or customer call transcripts to process. The pipeline navigator skill will route you to the right role if you’re unsure where to enter.
The skills are open-source. Contributions are expected. If a skill breaks for your environment, file an issue. If you’ve built something that improves one of these workflows, submit a PR. The engineering team is actively improving the skill set and the community feedback loop is the mechanism for that.
Next Steps
- Install CTI Domain Search and run it against one CVE you’ve been meaning to research. The difference in source quality versus a standard web search is immediately apparent.
- Try the Phoenix Pipeline on your next feature specification. Start with the context curator role and see how many security questions surface before you’ve written a single requirement.
- Contribute detection rules to the OpenGrep community using the rule generator skill. Converting your internal detection knowledge into reusable, shareable rules benefits the broader practitioner community.