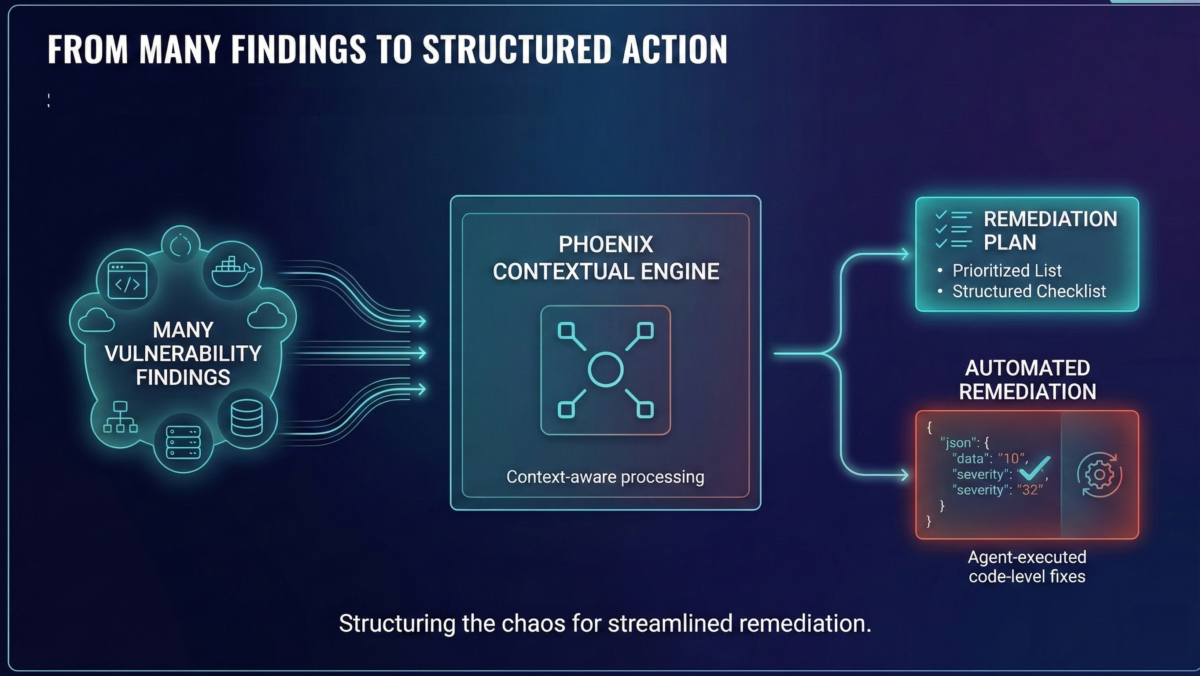
Security programs don’t fail because they miss vulnerabilities. They fail because they can’t convert findings into a small, reliable set of changes engineers will ship.
Phoenix Security is built around a single principle:
A vulnerability only matters if it maps to a change.
A change only matters if it reduces risk at scale.
That sounds obvious — until you look at how most tooling behaves: it produces lists, not plans. It reports duplicates, not outcomes. It optimizes for detection, not remediation velocity.
Phoenix treats remediation as an engineering problem: graph → reachability → ownership → minimum-impact fixes → measurable risk reduction.
The questions that drive remediation (and kill noise)
Phoenix is intentionally opinionated. It asks questions most products avoid because they require correlation across code, cloud, runtime, and ownership.
1) Is it reachable?
If the vulnerable code never executes, it shouldn’t compete with production-impacting issues.
- Is the vulnerable path invoked at runtime?
- Is the library present and loaded, or just present?
- Is the container even running?
2) Is it exploitable?
Severity without an exploitation context is a budgeting exercise, not a security decision (National Vulnerability Database).
- What threat signals exist?
- Is there evidence of exploitation?
- Can this vulnerability be reached (remote code execution) and can it be breach in memory (memory corruption)
- Does it align with ransomware activity or active campaigns?
- Are threat actor targeting this vulnerability?
3) Is it critical to the business?
Criticality is not “prod vs non-prod.” Phoenix uses a curve so business importance changes remediation urgency without rewriting the entire program.
- What does this service support?
- Who owns it?
- What is the blast radius?
4) What is the smallest change that removes the most risk?
This is the core differentiator. Phoenix reduces vulnerability management into remediation units:
- a minimal library bump that clears the most CVEs
- a base image upgrade that collapses OS-level duplicates
- an AMI fix that patches a fleet
- one code pattern fix in one file that clears a class of issues
If a platform can’t answer that, it can’t remediate. It can only report. Can an Agent convert a remediation into a series of code actions that deliver real value?
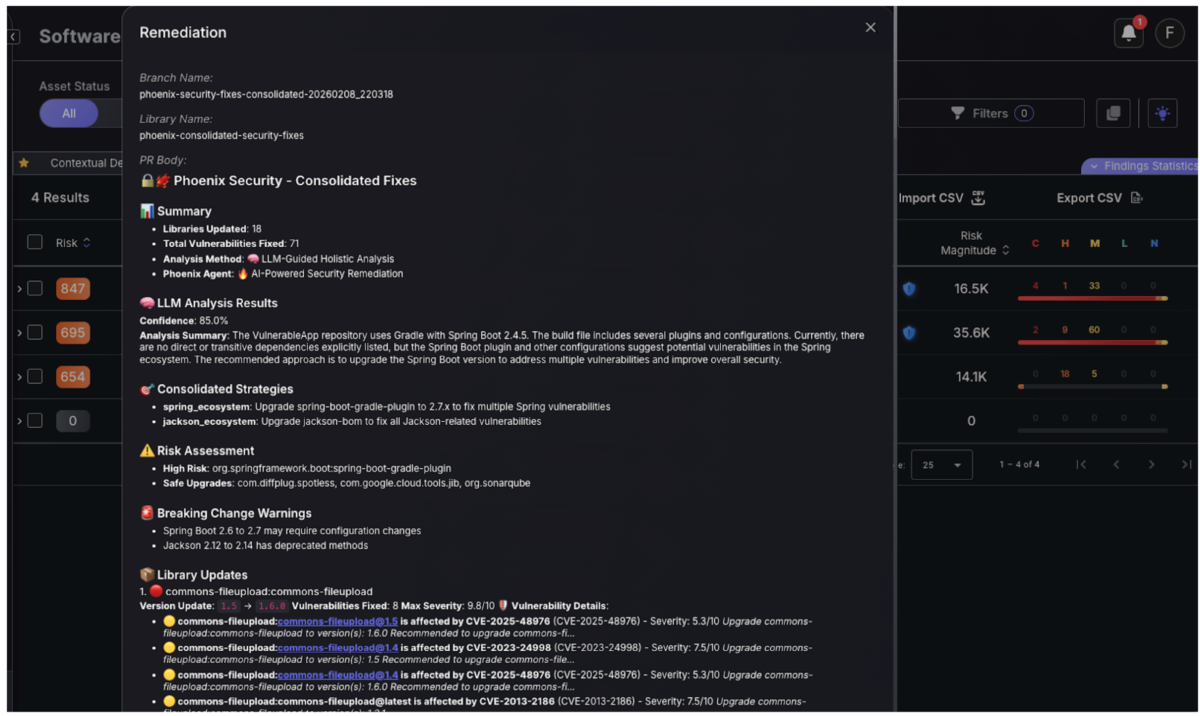
Remediation starts at the vulnerability layer, not at the dashboard
Phoenix models risk where it belongs: at the vulnerability layer, then aggregates upward.
Inputs include:
- scanner severity (CVSS)
- exploit likelihood signals
- fix availability
- exposure (externally reachable vs not)
- business criticality
That’s why Phoenix can collapse noise across applications, images, and environments while still producing defensible prioritization.
Demonstrable remediation: one CVE, two surfaces, one fix plan
Here’s a technical case that shows why remediation needs correlation.
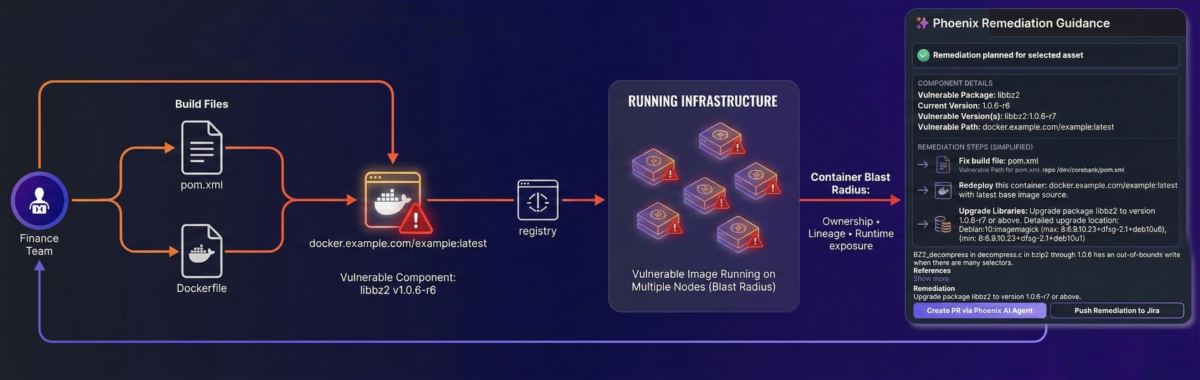
Scenario: bzip2 appears in code and the container, and it’s reachable
You run:
- Java/Spring service: finance-transaction-service
- Containerized into webapp_container_cluster in Cloud Prod
- Base image: python:2.7-slim (legacy stacks exist; pretending they don’t is how you lose runtime)
- App includes helper scripts that use Python’s bz2 module
The same risk gets reported twice
Container scanner:
- OS package libbz2 flagged (example: libbz2:1.0.6-r6)
- CVE appears at the container/OS layer
SCA / application scan:
- Compression stack pulls in:
- org.apache.commons:commons-compress
- org.apache.logging.log4j:log4j-core
- org.apache.commons:commons-compress
- Additional duplicates appear because the app artifact also carries SBOM inventory
Now the important part: reachability.
- The Python bz2 module links to libbz2
- If the service calls that script in production (migration, export, batch reports), the vulnerable component is not theoretical. It executes.

What Phoenix does: contextual deduplication into a remediation story
Without correlation, teams get multiple “fires”:
- “Fix libbz2 in the container”
- “Fix bzip2 in the app”
- “Upgrade commons-compress”
- “Upgrade log4j-core”
Phoenix builds the graph and collapses it:
- multiple components/apps → one vulnerability node → image registry layers → runtime cluster
- one remediation plan with proof: runtime placement + lineage + reachability
This is where remediation becomes demonstrable: you can point to exactly where the vulnerability lives and which change removes it.
Fix with remediaiton don’t chase ghost vulnerabilities
From 273 findings to 35 upgrades across 7 libraries
Your remediation table is the best proof of the philosophy.
Most tools hand you 273 findings and call it “visibility.” Phoenix treats that as failure.
Phoenix turns it into:
- 35 upgrade actions
- across 7 libraries
- selected to maximize impact with minimal blast radius
That happens through two mechanics:
1) Group by library across the entire graph
Phoenix groups findings into upgrade actions like:
- org.apache.commons:commons-compress: ≥ 1.21
- org.apache.logging.log4j:log4j-core: ≥ 2.3.1
- com.fasterxml.jackson.core:jackson-core: ≥ 2.15.0-rc1
This removes duplicates across:
- applications
- components
- images
- clusters
- scanners
2) Minimum-impact upgrade selection
Phoenix does not default to “latest everything.”
It targets:
- the lowest safe version
- that resolves the largest set of vulnerabilities
That single choice is why remediation stays shippable. It lowers break risk and reduces engineering resistance.
Implement code agents to deliver the vulnerabilities directly as code pull request
Remediation by domain: what Phoenix optimizes for
Phoenix doesn’t treat all findings the same. Each category has a different best remediation unit.
Infrastructure / laptop / server: patch outcome, not per-CVE work
Remediation unit: upgrade OS/product to the highest approved version
Why: recurring CVEs collapse when old baselines disappear.
Ask this in your program:
- Which patch removes the most critical risk across endpoints?
- Which teams own the systems still stuck on old OS versions?
Libraries (SCA): smallest upgrade, maximum coverage
Remediation unit: minimal version bump that clears the most CVEs
This is where “273 → 35” becomes real.
Ask this: What’s the smallest bump that resolves the most issues across all services?
Capability: SCA minimal-impact upgrades (available)
Containers: remove dead noise, trace fixes to build/base image lineage
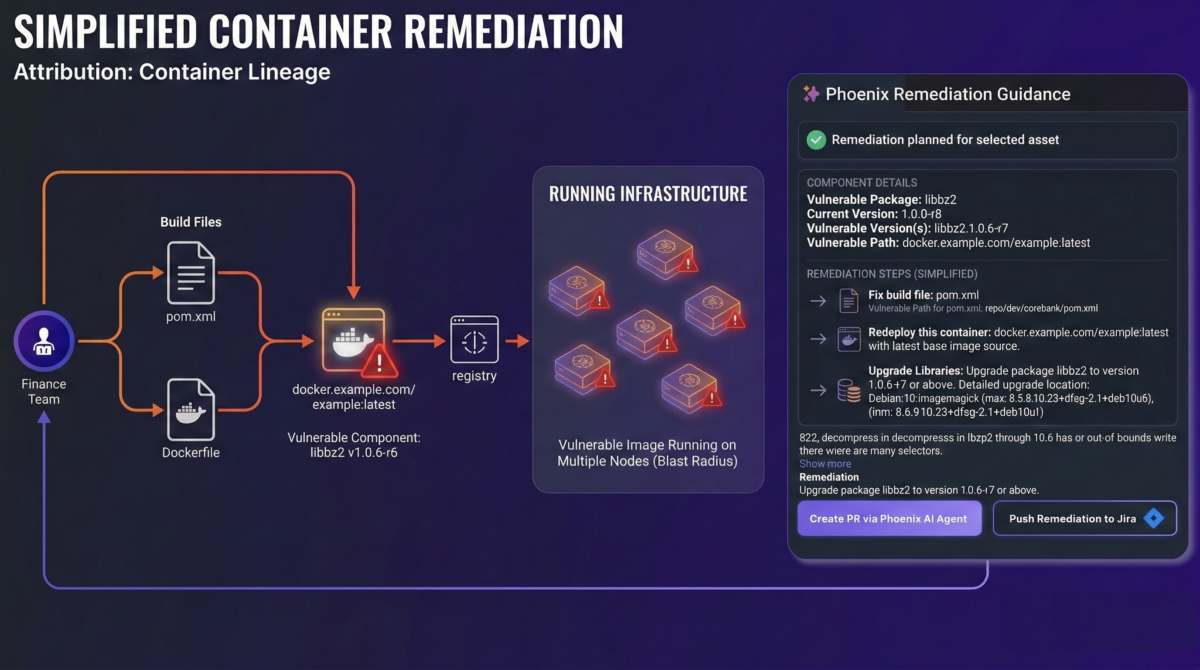
Remediation units:
- remove non-running containers (delete unsolvable noise)
- upgrade Dockerfile/build dependencies
- bump base image
- replace upstream external base image that generates downstream images
Ask this:
- Is the container running?
- Does the vulnerability come from the build file or the base image?
- Which upstream image generates the vulnerable fleet?
Capabilities: TRACE + THREAD lineage mapping (available); container-to-Dockerfile remediation (in release)
Code: fix the biggest class in a single file
Remediation unit: one pattern fix that clears a class of findings
Engineers ship patterns, not tickets.
Ask this: Which single file/class change removes the largest set of repeated issues?
Capability: AI SATS safe, high-impact code fixes (in release)
Secrets: stop repetition by removing the most frequent leak source
Remediation unit: eliminate the repeated secret source
Rotate, move to secret manager/env, add guardrails.
Ask this: Which secret type keeps reappearing, and where?
Capability: secrets removal + guardrails (upcoming)
Cloud workloads: patch the golden image, not every instance
Remediation unit: fix the AMI that produces the fleet
One change, many machines.
Ask this: Which AMI is generating the vulnerable footprint?
Cloud misconfig: fix the class, prevent reintroduction
Remediation unit: one IaC/policy correction that closes a family of exposures
Ask this: Which misconfig class is responsible for most repeat violations?
Capability: IaC/Terraform remediation (upcoming)
Execution: remediation that lands in engineering workflows
A remediation plan that never enters the delivery pipeline is theater.
Phoenix routes remediation as:
- Tickets (Jira, ServiceNow): upgrade X→Y, bump base image, rebase AMI, fix file/class
- Alerts (Slack, Teams): notify owner + evidence + expected impact
- Code fixes: PR-based changes where enabled
What a real ticket looks like
Title: Upgrade commons-compress + base image to eliminate bzip2 duplicates across Finance services
Body:
- Proof: reachable in Cloud Prod, traced through image lineage to runtime
- Remedies:
- org.apache.commons:commons-compress ≥ 1.21
- org.apache.logging.log4j:log4j-core ≥ 2.3.1
- rebase image to remove vulnerable libbz2
- org.apache.commons:commons-compress ≥ 1.21
- Expected outcome: 273 findings → 35 upgrade actions across 7 libraries
- Ownership: team + repo + service mapped
That’s a remediation story an engineer can ship.
The agent layer: AI that accelerates remediation, not decisions
Phoenix uses focused agents tied to specific remediation steps:
- Security Researcher Analyst Agent (Gemini): threat intel before it hits NVD, exploitation likelihood, ransomware risk, actor mapping
- Security Analyst Agent + PYRUS: attribution and grouping (developer-friendly CMDB behavior)
- TRACE + THREAD: build file → image → base image → runtime lineage + non-running container detection
- Risk & Analyzer (GRC): threat models + attack paths for faster human analysis
- Remediator: remediation plans + PR auto-fixes, minimum-impact changes for maximum coverage
- Copilot / Orchestrator: coordinates the agents and investigations via platform context
Use cases and results
Phoenix is built for AppSec teams chasing outcomes:
- Reduced reachable vulnerable code in containers by 78–91%
- Removed 430,000+ container vulnerabilities by eliminating non-running containers
- Cut SCA noise by up to 78% by connecting SCA to runtime
- Accelerated remediation by up to 10x without burning out engineers
Case studies:
FAQ: Remediation-first DevSecOps with Phoenix Security
What does “remediation-first vulnerability management” mean in DevSecOps?
It means the primary output is a small set of shippable changes, not a growing backlog of CVEs. Phoenix turns scanner findings across code, cloud, containers, endpoints, and infrastructure into remediation units: upgrade X→Y, rebase image, patch AMI, fix one code pattern, remove a secret source—then routes them into Jira/ServiceNow, Slack/Teams, or PRs.
How do I move from “40k vulnerabilities” to “12 fixes that matter”?
Stop prioritizing by CVSS alone. Phoenix prioritizes by Reachable + Exploitable + Critical:
- Reachable: does it execute in runtime?
- Exploitable: is there threat intel, active exploitation, ransomware linkage?
- Critical: does it sit on a business-critical service and exposed surface?
That combination collapses the backlog into a shortlist engineers can burn down.
How does Phoenix determine if a vulnerability is reachable in production?
Phoenix correlates findings to runtime context:
- container is running vs dead inventory
- vulnerable package is loaded vs merely present
- dependency path maps to a deployed service
- code-to-cloud links repo/build file → image → base image → cluster/runtime
Reachability is treated as a first-class signal that changes priority and remediation sequencing.
How do I reduce SCA noise without “accepting risk” or suppressing findings?
Phoenix reduces SCA noise by shifting from “finding count” to “upgrade actions”:
- deduplicates the same dependency issue across multiple apps/images
- groups by library + version constraint
- recommends the minimum safe upgrade that clears the maximum vulnerabilities
That’s how “273 findings” becomes “35 upgrades across 7 libraries.”
Why does Phoenix recommend “minimum safe version” instead of “upgrade to latest”?
Latest creates churn, regressions, and upgrade fatigue. Phoenix optimizes for coverage per change:
- pick the lowest version that fixes the most issues
- reduce the number of upgrades required across systems
- keep remediation acceptable to engineering teams
Remediation velocity rises because changes stop feeling like rewrites.
How do I remediate container vulnerabilities: Dockerfile vs base image vs upstream image?
Phoenix traces the vulnerability to the layer where a fix actually works:
- Build dependency (Dockerfile/build tooling): upgrade Maven/Gradle/npm/pip dependency
- Base image: rebase to patched base image or bump OS packages
- External upstream image lineage: patch the image that produces downstream images at scale
- Non-running containers: remove them and delete the noise immediately
This avoids the common failure mode: patching the wrong layer and watching findings reappear.
How does Phoenix handle vulnerabilities reported both by SCA and container scanning?
Phoenix correlates them into one remediation story using contextual deduplication. A single root cause (like libbz2 or a compression stack) often appears:
- as an OS package in the container
- as an app dependency chain in SCA/SBOM
Phoenix links them through runtime lineage and outputs a unified remediation plan: base image rebase + minimal dependency bump, with expected impact.
What’s the fastest way to cut container vulnerability volume without hiding issues?
Remove vulnerabilities from containers that don’t run. Non-running containers inflate counts and burn triage time. Phoenix identifies non-running containers and eliminates their vulnerability load, then focuses remediation on containers and images that actually execute in production.
How do I fix cloud workload vulnerabilities at scale?
Patch the source that produces the fleet. Phoenix targets:
- the golden image / AMI that generates many machines
- the remediation action that collapses exposure through one change event
This reduces repeat work and avoids per-instance patching that never finishes.
How do I remediate cloud misconfigurations without chasing resources one-by-one?
Phoenix focuses on misconfiguration classes:
- one policy or IaC correction that closes a family of exposures
- one change that prevents reintroduction during provisioning
This is where IaC-based remediation wins: fix the template, not the symptoms.
How does Phoenix create tickets engineers won’t ignore in Jira or ServiceNow?
Phoenix writes tickets as engineering actions with evidence and outcome:
- exact remedy (upgrade X→Y, rebase image, patch AMI, fix file/class)
- runtime proof (where it runs, why it’s reachable)
- scope (apps/assets/teams affected)
- expected impact (findings reduced + risk magnitude change)
- ownership attribution (team/repo/service)
It avoids “fix 273 vulnerabilities” tickets because those get closed by time, not by remediation.
What’s the difference between Discovery SLA and Remediation SLA in Phoenix?
Phoenix tracks two clocks:
- Discovery SLA: time from detection to acknowledgement
- Remediation SLA: time from work start (ticket open) to fix shipped
This separates “we didn’t know” from “we knew and didn’t act,” and supports clean reporting without gaming.
How do I stop SLA policies from becoming unachievable and ignored?
If everything is breaching, the SLA is unusable. Phoenix supports:
- one SLA matrix for clarity and board-level reporting
- automated SLA overrides for high-exposure assets (externally facing, high criticality)
The goal is a threshold that creates action, not a policy that trains teams to ignore it.
How do Phoenix AI agents help remediation without turning security into autopilot?
Agents are scoped to remediation steps:
- threat intel + exploitation prediction (Gemini)
- attribution and grouping (Security Analyst Agent + PYRUS)
- lineage mapping (TRACE + THREAD)
- threat models/attack paths for developer context (Risk & Analyzer)
- remediation planning + PR-ready changes (Remediator)
- orchestration across workflows (Copilot)
AI is used where it reduces toil and speeds fixes, not where it replaces judgment.
What metrics prove remediation is working (and can’t be gamed)?
Track metrics tied to outcomes:
- Findings → remedies compression ratio
- Risk reduction per remedy
- Reachable risk trend in production
- Mean time to open vs mean time to patch
- Remedies shipped per sprint by team
If one upgrade removes hundreds of findings and reduces reachable risk, that’s progress that survives scrutiny.
What’s the recommended rollout sequence for Phoenix remediation?
Start where remediation scales fastest:
- remove non-running containers
- rebase base images / patch golden images (AMI)
- apply minimum-impact dependency upgrades (SCA)
- fix repeated code patterns concentrated in a small number of files enforce secrets guardrails to stop reintroduction
This sequence drives measurable reduction without burning out engineering teams.
How Phoenix Security Fixes What Actually Matters
Your team doesn’t have a finding problem. They have a fixing problem.
Most platforms hand you a list. Phoenix hands you a plan — ranked by real risk, mapped to the team that owns it, with a clear path to close it.
What remediation looks like with Phoenix:
- One backlog, not five. Findings from SAST, SCA, containers, and cloud — deduplicated, correlated, and surfaced in a single prioritized queue. No more reconciling lists across tools.
- Ownership that sticks. Team attribution and inheritance mean the right ticket goes to the right engineer, first time. No routing, no guessing, no back-and-forth.
- Campaigns that move the needle. Group related findings into targeted remediation campaigns. Track progress, measure closure rates, and report real reduction — not raw counts.
- AI that does the legwork, not the deciding. Phoenix’s Remediator agent drafts fixes, creates tickets, and opens PRs. Your team reviews, approves, and merges. Every fix is traceable.
Phoenix Security changes the game.

The pattern is the same every time: teams that move from find and report to analyze and fix close more risk with less effort.

The results are clear:
- Bazaarvoice saved $6.3M in developer time and for teams removed critical in the first weeks of adoption
- ClearBank cut critical container vulnerabilities by 96–99% and reclaimed 4 hours per engineer per week.
- A global AdTech company saved an equivalent of 1.5M in development hours and reduced SCA-to-container noise by 82.4%
- Optimizely has been able to act on vulnerabilities sitting on the backlog.
Or learn how Phoenix Security slashed millions in wasted dev time for fintech, retail, and adtech leaders.